




 Contrary to Some Views, Google and Co.’s Microdata Effort will Also Boost RDF
Contrary to Some Views, Google and Co.’s Microdata Effort will Also Boost RDF
In my opinion, perhaps the most important event for the structured Web since RDF was released a dozen years ago was today’s joint announcement by the search engine triumvirate of Google, Bing and Yahoo! releasing Schema.org. Schema.org is a vendor specification for nearly 300 mini-schema (or structured record definitions) that can be used to tag information in Web pages. These schema are organized into a clean little hierarchy and cover many of the leading things — from organizations to people to products and creative works — that can be written about and characterized on the Web.
These schema specifications are based on the microdata standard presently under review as part of the pending HTML5 specification. Microdata are set record descriptions of key-value pair attributes that can be embedded into the HTML Web page language. These microdata schema are similar to microformats, but broader in coverage and extensible. Microdata is also simpler than RDFa, another W3C specification that the Schema.org organizers call “. . . extensible and very expressive, but the substantial complexity of the language has contributed to slower adoption.”
Is the Initiative a Slap in RDF’s Face?
Various forums have been alive with howls and questions from many RDF and RDFa advocates that this initiative negates years of effort behind those formats. Yet I and my company, Structured Dynamics, which base our entire technology approach on semantics and RDF, do not see this announcement as a threat or rejection. What gives; what is the difference in perspective?
In our view, RDF and its triple representations in its data model, is the simplest and most expressive means to represent any data or any data relationship. As such, RDF, and its language extensions such as OWL and ontologies, provide a robust and flexible canonical data model for capturing any extant data or schema. No matter what the native form of the source information, we can boil it down to RDF and inter-relate it to any other information. It is for these reasons (and others) we have frequently termed RDF as the universal data solvent.
But, simple records and simple data need not be encumbered with the complexity of RDF. We have long argued for the importance of naive data structs. Many of these are simple key-value pairs where the subject is implied. The so-called little structured data records in Wikipedia, called infoboxes, are of this form. JSON and many simple data formats also have cleaner data formats.
The basic fact that RDF provides a universal data model for any kind of native data does not necessarily translate into its use as the actual data exchange format. Rather, winning data exchange formats are those that can be easily understood, easily expressed and therefore widely used. I think there is a real prospect that microdata, ready for ingest and expression by the Web’s leading search engines, may represent a real sea change in the availability and expression of structured data on the Web.
More structure — not less — is the real fuel that will promote greater adoption of RDF when it comes time to interoperate that data. The RDF community should rejoice that more structure will be coming to the Web from Google et al.’s announcement. We should also soon see an explosion of tools and utilities and services that make it easy to automatically add such structure to Web pages via single clicks. Then, once this structure is available, watch out!
So, while the backers of Schema.org also announced their continued support for microformats and RDFa as they presently exist, I rather suspect today’s announcement represents a denouement for these alternative formats. Though these formats may be creatively destroyed, I think the effect on RDF itself will be a profound and significant boost. I foresee clarity coming to the marketplace regarding RDF’s role: as a canonical means for expressing data of any form, and not necessarily as a data exchange format.
The Initiative is No Surprise
This initiative, led by Google, should be no surprise. Google is the registered agent for the Schema.org Web site and has been the key proponent of microdata via its support of Ian Hickson in the WhatWG and HTML5 work groups. As I stated a couple of years back, Google has also not hidden its interests in structured data. Practically daily we see more structured data appear in Google search results and it has maintained a very active program in structured data extraction from text and tables for some years.
Google and its search engine partners recognize that search needs are evolving from keyword retrievals to structure, relationships, and filtered, targeted results. Those advances come from structure — as well as the semantic relationships between things that something like the Schema.org begins to represent.
Many within the W3C and elsewhere questioned why Google was pushing microdata when there were competing options such as microformats or RDFa (or even earlier variants). Of course, like Microsoft of a decade earlier, some ascribed Google’s microdata advocacy as arising from commercial interests or clout in advertising alone. Of course Google has an economic interest in the growth and usefulness of the Web. But I do not believe its advocacy to be premised on clout or “my way or the highway.”
Google and the search engine triumvirate understand well — much better than many of the researchers and academics that dominate mailing list discussions — that use and adoption trump elegance and sophistication. When one deconstructs the design of microdata and the nearly 300 schema now released behind it, I think the pragmatic observer can only come to one conclusion: Job well done!
Why This is Exciting
I have been a fervent RDF advocate for nearly a decade and have also been a vocal proponent of the structured Web as a necessary stepping stone to the semantic Web. In fact, here is a repeat of a diagram I have used many times over the past 5 years:
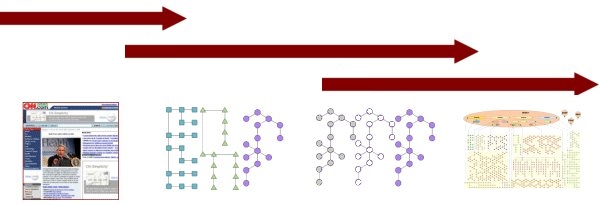 |
|||
| Document Web | Structured Web |
Semantic Web
|
|
| Linked Data | |||
|
|
|
|
When one looks at the schema of schema that accompany today’s announcement, it is really clear just how encompassing and important these instant standards will become:
Today’s announcement is the best news I have heard in years regarding the structured Web, RDF, and the semantic Web. This announcement is — I believe — the signal event of the structured Web. With regard to my longstanding diagram above, I can go to bed tonight knowing we have now crossed the threshold into the semantic Web.

Terrific post with great perspective !
I keep reading how this is great for RDF, but I have also read on Google’s site…
“One caveat to watch out for: while it’s OK to use the new schema.org markup or continue to use existing microformats or RDFa markup, you should avoid mixing the formats together on the same web page, as this can confuse our parsers.”
http://googlewebmastercentral.blogspot.com/
And so I am having trouble finding the win here for RDF.
You have an interesting point there, however IMHO it is not enough: One of the distinctive features of RDF and semantic technologies is the capability of naming (uniquely) and linking. As far as I understand, these features are not possible using schema.org, since all what they do is to give structure to the content and provide some typing mechanism (the fact that you can extend the classes without a disambiguation mechanism like namespaces, makes it even worse).
Nicely done Mike! I think serious technologists and strategists involved with semantic web and search are very excited to see this development. I echo your sentiment, “it’s the best news I’ve heard in years.” Thanks for sharing, great post!
The choice of Microdata and excluding RDFa and microformats is a terrible direction for the web. It is silly to claim that developers can’t handle the choice of 3 formats. The only format of the 3 with an expansion strategy is RDFa. To exclude it from support at the beginning is a blatant political maneuver by the Microdata promoters, which is very much not in the spirit of the Web. Considering the trivial mapping from Microdata to RDFa makes it even clearer that their choice was not based on technical considerations, simply personal agendas. People expect this behavior from Microsoft, but people expect better from Google and Yahoo!.
Will Schema.org propel RDF adoption in the long run? I don’t know, but one thing should be clear: RDF is a toolset for those who wish to develop semantically enabled data sets, whereas Schema.org is merely a set of pre-defined stamps that might (MIGHT) be useful to someone semantically enriching their data. Thus I see two problems with Schema.org.
First, semantics do not exist in themselves, they grow out of communities in practice; ontology development using RDF as a toolset helps to document semantics as used by some community, but it also encourages the DISCUSSION which is where the true shared understanding develops.
Second, Schema.org is simply a vocabulary, whereas RDF enables any statement to be formed, without requiring consistency with the vocabulary used by others, while allowing identities between statement sets. In other words, using the Schema.org vocabulary only allows one to say what the Schema.org principles intend one to be able to say. Making finer distinctions than those anticipated by Microsoft, Google, and Yahoo is impossible, but ambiguity is still possible. That is, Schema.org says I can tag the text chunk “Seikai no Senki” as a TVSeries, but it doesn’t anticipate that this also refers to a series of novels and short stories, and I want to have conversations about the setting and characters that are utilized regardless of the commodities or media used to convey them. Besides “Seikai no Senki” is often referred to in translated form (as “Banner of the Stars”), and regardless of the textual deviation, they share an identity. RDF has no problem dealing with any of this.
In short, Schema.org strikes me as a convenience for the big three search engines, not a solution for the millions of people who use the web.