




Timelines, Semantics and Ontologies are Coming to the Fore
The past two weeks have seen an interesting emergence of new perspectives on the ‘deep Web‘. The deep Web, a term Thane Paulsen and I coined for my oft-quoted study from 2000, The Deep Web: Surfacing Hidden Value [1], is the phenomenon of database-backed content served from interactive Web search forms.
Because deep Web content is dynamic and produced only on request, it has been difficult for traditional search engines to index. It is also huge and of high quality (though likely not the 100x to 500x figure larger than the standard ‘surface’ Web that I used in that first study.)
Deep Web Timeline
This is the most recent of the three notable events over the past two weeks, and came out on Tuesday. Maureen Flynn-Burhoe of the oceanflynn @ Digg blog has produced a very informative and comprehensive timeline of deep Web and related developments from 1980 to the present (database-backed content and early Web precursors, of course, precede the Web itself and the term ‘deep Web’).
I have been directly involved in this field since 1994 and have not yet seen such a comprehensive treatment. She cites studies noting “hundreds of thousands” of deep Web sites and the faster growth of dynamic (database-served) as opposed to static (‘surface’) content on the Web.
As someone directly involved in estimating the size of the deep Web, I appreciate the analytic difficulties and take all of the estimates (my own older ones included!) with a grain of salt. Nonetheless, the deep Web is important, its content is huge, often of unique and high quality, and it deserves serious attention by Web scientists.
Great job, Maureen! I always appreciate thorough researchers. (BTW, I suspect you might also like the Timeline of Information History.)
Trends and Role in the Semantic Web
 The next notable event was the publishing of Searching the Deep Web by Alex Wright in the Communications of the ACM (October 2008) [2]. Alex had first written about the deep Web for Salon magazine in 2004 and had given nice attention to my company at that time, BrightPlanet [3].
The next notable event was the publishing of Searching the Deep Web by Alex Wright in the Communications of the ACM (October 2008) [2]. Alex had first written about the deep Web for Salon magazine in 2004 and had given nice attention to my company at that time, BrightPlanet [3].
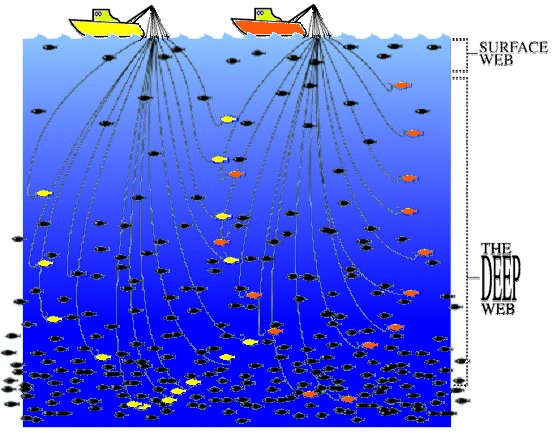
In this current update, Alex does an excellent job of characterizing current status and research in search techniques for the deep Web. I also liked the fact he used our fishing analogy of trawling for standard search crawlers versus direct angling in the deep Web (see our earlier figure at upper left).
As some may recall, Google has stepped up its activities in this area, an event I reported on a few months back. Those perspectives, and others from some other notable figures, are included in Alex’s piece as well.
My own contribution to the piece was to suggest that RDF and semantic Web approaches offered the next evolutionary stage in deep Web searching. Alex was able to take that theme and get some great perspectives on it. I also appreciate the accuracy of my quotes, which gives me confidence in the quality for the rest of the story.
Without a doubt there is high quality in the deep Web and bringing structure and semantic characterization to it through metadata is a task of some consequence.
For myself, I chose to move beyond the deep Web when its focus seemed stuck in a document-level perspective to retrieval and analysis. However, there is much to be learned from the techniques used to select and access deep Web content, which could be readily transferable to linked data.
Thanks, Alex, for making these prospects clearer! Maybe it is time to dust off some of my old stuff!
Getting Deeper into the Semantics

This emerging joining of deep Web and semantics is actually taking place through the efforts of a number of academic researchers. Recently and prominently has been James Geller from the New Jersey Institute of Technology and his colleagues Soon Ae Chun and Yoo Jung [4]. Their recently published paper, Toward the Semantic Deep Web, shows how ontologies and semantic Web constructs can be combined to more effectively extract information from the deep Web. They call this combination the ‘semantic deep Web.’
The authors posit that the structured roots of deep Web content lend themselves to better ontology learning from the Web. They also point to the usefulness of deep Web structure to annotations.
That such confluences are occurring between the semantic and deep “Webs” is a function of focused academic attention and the growing maturity of both perspectives. This year, for example, saw the inauguration of the first Workshop on Advances in Accessing Deep Web (ADW 2008). As part of the International Conference on Business Information Systems (BIS 2008), this meeting saw a lot of elbow rubbing with semantic Web and enterprise topics.
It might seem strange (indeed, sometimes it does to me 😉 ) to envision structured database content being served through a Web form and then converted via ontologies and other means to semantic Web formats. After all, why not go direct to the data?
And, of course, direct conversion is less lossy and more efficient.
But, one interesting point is that semantic Web techniques are increasingly working as a structure-extraction layer wrapping the standard Web. In that regard, starting with inherently structured source data — that is, the deep Web — can lead to higher quality inputs across the distributed, heterogeneous content of the Web.
Given the impossibility of everyone starting with the same premises and speaking the same languages and concepts, semantic Web mediation methods offer a way to overcome the Tower of Babel. And, when the starting content itself is inherently structured and (generally) of higher quality — that is, the deep Web — the logic of the combination becomes more obvious.
For More Information
Interested in learning more about the deep Web? I firstly recommend the resources posted at the bottom of Flynn-Burhoe’s timeline. And, for a very thorough treatment, I also recommend Denis Shestakov’s Ph.D. thesis from earlier this year [5]. It has a bibliography of some 115 references.

Hi Michael I am a student of cyber-psychology in Ireland. I was hoping you could direct me to any up to date figures on the size of the under web, the amount of information stored there etc. I understand from reading your papers etc that this is easier said than done but any assistance would be greatly received. kind regards Darren Noakes