




Wikipedia is an Essential — but Insufficient Alone — Organizing Subject Basis for the Structured Web
There are some really, really exciting events converging around the idea of RDF and exposed meaningful data and the ways (OK, yes, ontologies) to organize it. We have seen important announcements in recent weeks by Freebase and DBpedia, among others, that show how RDF and related data forms are being exposed on the Web for large and meaningful datasets. These are the structured Web precursors to the semantic Web.
There are also some really cool browsers and data navigators that are being tested and floating around at present.
Four Current Examples
What is shown below are four current alternatives for accessing and querying Wikipedia content in various structured ways. Each shares many of the same aspects and each has slight differences from the others. All four are experimental to some degree and most have somewhat unrefined interfaces:
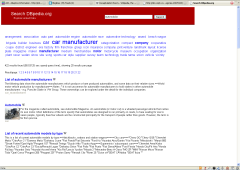
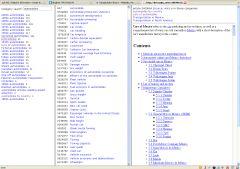
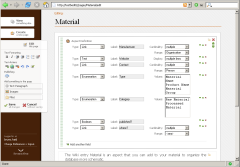
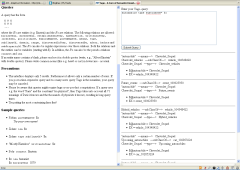
These four systems in clockwise order from upper left are:
- Search DBpedia — I earlier covered DBpedia in some detail, which is mostly a conversion of Wikipedia to RDF, though it does include some other datasets. The new search interface from Georgi Kobilarov is what is shown above
- Metaweb Explorer — this tool is from the developers of Freebase and works directly against Wikipedia categories and data; it is used to semi-automatically select and clean-up many of the categories and name-value pairs in templates and infoboxes prior to uploading en masse to Freebase (see further)
- YAGO Experimental — this innovative approach using a conceptual variant to RDF involves “yet another great ontology” (YAGO) which is a combination of subject structure from Wikipedia as refined by WordNet synsets. A very interesting paper on this approach is found at the authors’ Max Planck Institute Saarbrücken Web site, and
- System One’s Wikipedia3 — this is the first of the Wikipedia conversions to RDF. It also uses a more structured ontology, largely based on WikiOnt, but also elements of SKOS and Dublin Core (no direct online demo; must have access via System One).
In each of the cases above, a general query on the subject of automobiles was posed to the services. Queries around such topics, while producing many additional appropriate and related topics, also failed to produce a “natural” feeling organizational structure, such as within a subject tree, that would aid browsing or discovery. For example, getting a simple listing of automobile nameplates is generally quite difficult with these systems.
Still Missing Some Vertebrae
These four examples thus point to a real problem: the lack of a referential subject or topic structure around which to organize and access all of this emerging online data. Current attempts to do so based solely on Wikipedia fall significantly short (IMHO). (In fact, the Metaweb Explorer is designed expressly to help overcome this problem.)
That is because the starting basis of Wikipedia information has been built entirely from the bottom up — namely, what is a deserving topic. This has served Wikipedia and the world extremely well, with now nearly 7 million articles online. As socially-driven and -evolving, I foresee Wikipedia to continue to be the substantive core at the center of a knowledge organizational framework for some time to come. To use the backbone analogy of this posting, Wikipedia forms the spinal cord.
But to complete the backbone, more structure is needed.
Wikipedia itself provides much useful structure. There is an internal categorization system (which is the subject organizational basis for much of the four examples noted above), plus its templates and infoboxes. My earlier article described many of these.
Yet I find it interesting that the group at the Max Planck Institute layered on WordNet to provide greater semantic richness and structure to Wikipedia to derive its YAGO ontology, while System One embraced the specific RDFS framework of the Simple Knowledge Organization Systems (SKOS) to provide hierarchical and other structure. I believe both of these attempts are right on target and are adding more vertebrae — more strength — to this backbone.
The W+W+S+? Equation
I thus believe that a suitable subject structure for organizing knowledge is both needed and must be adaptable and self-defining. These criteria reflect expressions of actual social usage and practice, which of course changes over time as knowledge increases and technologies evolve.
Wikipedia provides the bottom-up basis for this subject structure; WordNet provides a contextual richness based on the evolving nature of language, and SKOS provides a representational schema for communicating this structure in RDF. Thus, W + W + S are part of the vertebrae in this subject structure.
Yet there still seems to be a missing piece. Namely, the remaining question mark is the actual top-down superstructure of subject and topic organization. Unlike historical systems (such as the Dewey Decimal System or the Library of Congress Subject Headings), and unlike grand schemas developed by committees or standards bodies, I think that such structure must also evolve from the global community of practice, as has Wikipedia and WordNet. (That does not mean that everyone votes on such things or that the process is democratic with a small d, just simply that there is an open process whereby anyone of interest may contribute or challenge. This can be a general contributory process such as how Wikipedia developed, or a derivation from actual usage as is the case with WordNet.)
In classical plant or animal phylogenies developed by systematicists, classification systems are called “natural” that reflect the actual nature of relationships among organisms. I think it should also be possible to discover more “natural” (as opposed to imposed, arbitrary or “artificial”) systems for classifying knowledge as subjects as well. In fact, we likely already have the raw grist to do so based on folksonomies, large numbers of Web searches, further processing of WordNet and Wikipedia, or similar primary data. (The Freebase approach may also show promise.)
Like WordNet itself, such starting data could be analyzed for subject hierarchies and relationships. Such ontology learning methods from text are well-advanced (or, rather, sufficiently advanced to provide a first-generation hierarchical subject structure). Perhaps a grand challenge against a large contextual Web term set could provide the basis for choosing a representative basis for such a top-down subject structure. This could be the missing vertebra in the W + W + S + ? backbone.
Finally, as with all of the other pieces of the backbone, no one is looking for the best and final answer. All we are looking for today is a satisficing answer that can gain the trust and acceptance of the global online community. Something is better than nothing.
There’s plenty of time to adapt and refine such methods into the future.

To All,
Shortly after posting this piece, I heard from Robert Cook at Metaweb correcting some initial errors in what the Metaweb Explorer does and its purpose to clean-up original Wikipedia structure. I have now made those corrections in the main body of the piece. Thanks, Robert! And I apologize for the initial errors.
But Robert also went on to observe other germane activities that Metaweb is undertaking in connection with Freebase. I quote Robert in full:
Freebase is attempting to fix exactly this problem [of lack of a governing subject structure]. The experts in a domain understand the structure much better than formal ontologists or data modelers. We’re trying to build tools for them to do so. We’re also creating the community mechanisms for users of the data to help give relevant feedback so that schemas can evolve in the right direction. It’s neither ‘top down’ nor ‘bottom up’ — it’s more like ‘middle out’ with a lot of communication. Right now, it’s very early and we haven’t proven this model, but we’re hopeful.
Thanks, Robert. I know all of us will be monitoring Freebase’s development with keen interest.
Mike
I really like the use of a vertbrae analogy, because if you think about a backbone, each disc is seperately very ridge and provides alot of strength, but the loose links between the discs is what gives the backbone its flexibility. Likewise, the ultimate solution will need to provide a lot of (formal) structure and consistency, but be flexible enough to encompass all the different ways people will use and apply knowledge in the Semweb. Open collaboration of ontology development, e.g. a Wikitology, is one way to bring ontologies out of the silos and vacuums in which they are currently being created. Wikipedia is an example that such an approach can provide the consensus and the mass needed, both in bredth, and dept of this backbone. I also think one thing missing from your analysis is context. Take your Automobile example. In some contexts and for some users, for instance a user looking up an automobile’s history, a nameplate would be a “natural” property of a car, and the interface should mold around that and other properties. But for other contexts and users, for example a metal scrap yard owner looking up vehicles in his inventory, other “views” of car are more appropriate (weight for example). So the backbone (e.g. wikitology) will need to account for this kind of context, allowing and allow users to switch from one context to another as they transverse the data in this structured web.
Hi Sherman,
I’m glad you like the vertebrae analogy. In some subsequent pieces I’m working on I extend the analogy to also relate to how other specific domains — the many other body parts in the organism — also tie into (“hang off of”) this backbone structure. What I’m really thinking about is a simple, lightweight binding structure to which any and all third-party ontologies and structures can reference in relation to their subject coverage. This would greatly aid such things as guiding queries to SPARQL endpoints, collaborative P2P frameworks such as DBin, prompting vocabularies and structures for newly developed ontologies, etc.
I also totally concur with your views on context. But even in the case of an ambiguous term such as “driver”, an appropriate subject structure could have many placements related to golf, printers, automobilies. screws, NASCAR, whatever. In fact, such structure itself helps guide the context by virtue of which branches in the subject tree are of primary interest (i.e., enables disambiguation). (I’m also not ignoring relatedness, one reason why I like SKOS as reference schema.)
I’d be curious to know how we could direct the NLP tool you have written, Cypher, to Wikipedia, Cyc, and WordNet to make this happen. Interested?
Mike