




It is truly amazing — and very commonly overlooked — to see how much progress has been made in the past decade to overcoming what had then been perceived as close-to intractable data interoperability and federation issues.
It is easy to forget the recent past.
In various stages and in various ways, computer scientists and forward-looking users have focused on many issues related to how to maximize the resources being poured into computer hardware and software and data collection and analysis over the past two decades. Twenty years ago, some of the buzz words were portability. data warehousing and microcomputers (personal computers). Ten years ago, some of those buzz words were client-server, networking and interoperability. Five years ago, the buzz words had shifted to dot-com and e-commerce and interoperability (now called ‘plug-and-play’). Today, among many, the buzz words could arguably include semantic Web, Web 2.0 and interoperability or mashups.
Of course, the choice of which buzz words to highlight is from the author’s perspective, and other buzz words could be argued as more important. That is not the point. Nor is the point that fads or buzz words come and go.
But changing buzz words and trends can indeed mask real underlying trends and progress. So the real point is this: Don’t blink, some real amazing progress has taken place overcoming data federation and interoperability in the last 15 to 20 years.
The ‘Data Federation’ Imperative
“Data federation” — the important recognition that value could be unlocked by connecting information from multiple, separate data stores — first became a research emphasis within the biology and computer science communities in the 1980s. It also gained visibility as “data warehousing” within enterprises by the early-90s. However, within that period, extreme diversity in physical hardware, operating systems, databases, software and immature networking protocols hampered the sharing of data. It is easy to overlook the massive strides in overcoming these prior obstacles in the past decade.
It is instructive to turn back the clock and think about what issues were preoccupying buyers, users and thinkers in IT twenty years ago. While the PC had come on the scene, with IBM opening the floodgates in 1982, there were mainframes from weird 36-bit Data General systems to DEC PDP minicomputers to the PCs themselves. Even on PCs, there were multiple operating systems, and many then claimed that CP/M was likely to be ascendant, let alone the upstart MS-DOS or the gorilla threat of OS/2 (in development). Hardware differences were all over the map, operating systems were a laundry list two pages long, and nothing worked with anything else. Computing in that era was an Island State.
So, computer scientists or users interested in “data federation” at that time needed to first look to issues at the iron or silicon or OS level. Those problems were pretty daunting, though clever folks behind Ethernet or Novell with PCs were about to show one route around the traffic jam.
Client-server and all of the “N-tier” speak soon followed, and it was sort of an era of progress but still costly and proprietary answers to get things to talk to one another. Yet there was beginning to emerge a rationality, at least at the enterprise level, for how to link resources together from the mainframe to the desktop. Computing in that era was the Nation-state.
But still, it was incredibly difficult to talk with other nations. And that is where the Internet, specifically the Web protocol and the Mozilla (then commercially Netscape) browser came in. Within five years (actually less) from 1994 the Internet took off like a rocket, doubling in size every 3-6 months.
Climbing the ‘Data Federation’ Pyramid
So, the view of the “data federation” challenge, as then articulated in different ways, looked like a huge, imposing pyramid 20 years ago:
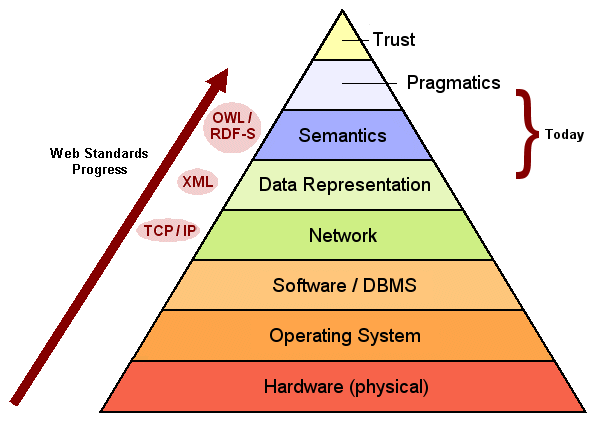
Rapid Progress in Climbing the Data Federation Pyramid
It is truly amazing — and very commonly overlooked — to see how much progress has been made in the past decade to overcoming what had been perceived as close-to intractable data interoperability and federation issues a mere decade or two ago.
Data federation and resolving various heterogeneities has many of its intellectual roots in the intersection of biology and computer science. Issues of interoperability and data federation were particularly topical about a decade ago, in papers such as those from Markowitz and Ritter,[1] Benton,[2] and Davidson and Buneman.[3] [4] Interestingly, this very same community was also the most active in positing the importance (indeed, first defining) “semi-structured” data and innovating various interoperable data transfer protocols, including XML and its various progenitors and siblings.
These issues of data federation and data representation first arose and received serious computer science study in the late 1970s and early 1980s. In the early years of trying to find standards and conventions for representing semi-structured data (though not yet called that), the major emphasis was on data transfer protocols. In the financial realm, one standard dating from the late 1970s was electronic data interchange (EDI). In science, there were literally tens of exchange forms proposed with varying degrees of acceptance, notably abstract syntax notation (ASN.1), TeX (a typesetting system created by Donald Knuth and its variants such as LaTeX), hierarchical data format (HDF), CDF (common data format), and the like, as well as commercial formats such as Postscript, PDF (portable document format), and RTF (rich text format).
One of these proposed standards was the “standard generalized markup language” (SGML), first published in 1986. SGML was flexible enough to represent either formatting or data exchange. However, with its flexibility came complexity. Only when two simpler forms arose, namely HTML (HyperText Markup Language) for describing Web pages and (much later) XML (eXtensible Markup Language) for data exchange, did variants of the SGML form emerge as widely used common standards.[5]
The Internet Lops Off the Pyramid
Of course, midway into these data representation efforts was the shift to the Internet Age, blowing away many previous notions and limits. The Internet and its TCP/IP protocols and XML standards for “semi-structured” data and data transfer and representations, in particular, have been major contributors to overcoming respective physical and syntactical and data exchange heterogeneities, also shown by the data federation pyramid above.
The first recorded mentions of “semi-structured data” occurred in two academic papers from Quass et al.[6] and Tresch et al.[7] in 1995. However, the real popularization of the term “semi-strucutred data” occurred through the seminal 1997 papers from Abiteboul, “Querying semi-structured data,” [8] and Buneman, “Semistructured data.” [9]
One could thus argue that the emergence of the “semi-structured data” construct arose from the confluence of a number of factors:
- The emergence of the Web
- The desire for extremely flexible formats for data exchange between disparate databases (and therefore useful for data federation)
- The usefulness of expressing structured data in a semi-structured way for the purposes of browsing, and
- The growth of certain scientific databases, especially in biology (esp., ACeDB), where annotations, attribute extensibility resulting from new discoveries, or a broader mix of structural and text data was desired.[9]
Semi-structured data, as all other data structures, needs to be represented, transferred, stored, manipulated or analyzed, all possibly at scale and with efficiency. It is often easy to confuse data representation from data use and manipulation. XML provides an excellent starting basis for representing semi-structured data. But XML says little or nothing about these other challenges in semi-structured data use.
Thus, we see in the pyramid figure above that in rapid-fire order the Internet and the Web quickly overcame:
- Federation challenges in hardware and OSes and network protocols; namely the entire platform and interconnection base to the pyramid and the heretofore daunting limitations to interoperability
- A data representation protocol — solved via XML — that was originally designed for extensibility but became ubiquitous for a standard in data transfer
- A shift in attention from the physical to the metaphysical.
Shifting from the Structure to the Meaning
With these nasty issues of data representation and interconnection now behind us, it is not surprising that today’s buzz has shifted to things like the semantic Web, interoperabiility, Web 2.0, “social” computing, and the like.
Thus, today’s challenge is to resolve differences in meaning, or semantics, between disparate data sources. For example, your ‘glad’ may be someone else’s ‘happy’ and you may organize the world into countries while others organize by regions or cultures.
Resolving semantic heterogeneities is also called semantic mediation or data mediation. Though it displays as a small portion of the pyramid above, resolving semantics is a complicated task and may involve structural conflicts (such as naming, generalization, aggregation), domain conflicts (such as schema or units), data conflicts (such as synonyms or missing values) or language differences (human and electronic encodings). Researchers have identified nearly 40 discrete possible types of semantic heterogeneities (this area is discussed in a later post).
Ontologies provide a means to define and describe these different “world views.” Referentially integral languages such as RDF (Resource Description Framework) and its schema implementation (RDF-S) or the Web ontological description language (OWL) are leading standards among other emerging ones for machine-readable means to communicate the semantics of data. These standards are being embraced by various communities of practice; today, for example, there are more than 15,000 OWL ontologies. Life sciences, physics, pharmaceuticals and the intelligence sector are notable leading communities.
The challenge of semantic mediation at scale thus requires recognition and adherence to the emerging RDF-S and OWL standards, plus an underlying data management foundation that can handle the subject-object-predicate triples basis of RDF.
Yet, as the pyramid shows, despite massive progress in scaling it, challenges remain even after the daunting ones in semantics. Matching alternative schema (or ontologies or “world views”) will require much in the nature of new rules and software. And, vexingly, at least for the open Internet environment, there will always the the issue of what data you can trust and with what authority.
These are topics for subsequent posts regarding the semantic Web ‘stack’ and challenges in resolving semantic heterogeneities.
[1] V.M. Markowitz and O. Ritter, “Characterizing Heterogeneous Molecular Biology Database Systems,” in Journal of Computational Biology 2(4): 547-546, 1995.
[2] D. Benton, “Integrated Access to Genomic and Other Bioinformation: An Essential Ingredient of the Drug Discovery Process,” in SAR and QSAR in Environmental Research 8: 121-155, 1998.
[3] S.B. Davidson, C. Overton, and P. Buneman, “Challenges in Integrating Biological Data Sources,” in Journal of Computational Biology 2(4): 557-572, 1995.
[4] S.B. Davidson, G.C. Overton, V. Tannen, and L. Wong, “BioKleisli: A Digital Library for Biomedical Researchers,” in International Journal on Digital Libraries 1: 36-53, 1997.
[5] A common distinction is to call HTML “human readable” while XML is “machine readable” data.
[6] D. Quass, A. Rajaraman, Y. Sagiv, J. Ullman and J. Widom, “Querying Semistructured Heterogeneous Information,” presented at Deductive and Object-Oriented Databases (DOOD ’95), LNCS, No. 1013, pp. 319-344, Springer, 1995.
[7] M. Tresch, N. Palmer, and A. Luniewski, “Type Classification of Semi-structured Data,” in Proceedings of the International Conference on Very Large Data Bases (VLDB), 1995.
[8] Serge Abiteboul, “Querying Semi-structured data,” in International Conference on Data Base Theory (ICDT), pp. 1-18, Delphi, Greece, 1997. See http://dbpubs.stanford.edu:8090/pub/1996-19.
[9] Peter Buneman, “Semistructured Data,” in ACM Symposium on Principles of Database Systems (PODS), pp. 117-121, Tucson, Arizona, May 1997. See http://db.cis.upenn.edu/DL/97/Tutorial-Peter/tutorial-semi-pods.ps.gz.
