




The previous posting in this series described climbing the data federation pyramid and the progress that had been made in the last decade overcoming seemingly intractable problems involving hardware, software and networks. Key enablers for that progress were adoption of Internet protocols (TCP/IP, HTML) and adoption of the XML data representation standard.
Data Federation Wanes, Semantic Web Waxes
Through the late 1990s the focus of the data federation challenge matured to overcoming federations in meaning. Today, we know this challenge to be called the semantic Web or semantic mediation. The intellectual trigger for this shift in emphasis came from Tim Berners-Lee, James Hendler, and Ora Lassila when they described their “grand vision” for the semantic Web in a Scientific American article in 2001. [1] The authors described the semantic Web as:
To date, the World Wide Web has developed most rapidly as a medium of documents for people rather than of information that can be manipulated automatically. By augmenting Web pages with data targeted at computers and by adding documents solely for computers, we will transform the Web into the Semantic Web. Computers will find the meaning of semantic data by following hyperlinks to definitions of key terms and rules for reasoning about them logically. The resulting infrastructure will spur the development of automated Web services such as highly functional agents. Ordinary users will compose Semantic Web pages and add new definitions and rules using off-the-shelf software that will assist with semantic markup.
Berners-Lee had already been proselytizing on this topic for a few years, notably in his Weaving the Web book in 1999.[2] But the Scientific American article really popularized the topic.
Researchers in the field came to rely on a diagram that Berners-Lee had also developed to explain the various protocols and challenges underlying semantic Web technologies. This diagram, often affectionately called the “birthday cake,” has gone through many iterations. Here is one of the most widely reproduced versions from a Berners-Lee talk given in 2000: [3]
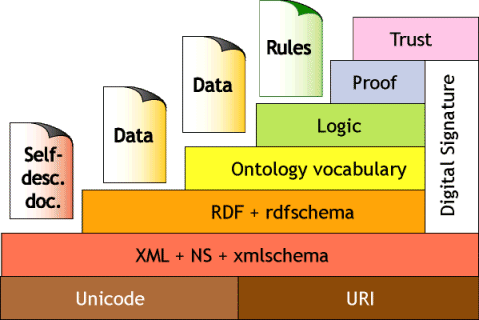
The Berners-Lee Semantic Web ‘Birthday Cake’
The Layers
Note that this diagram expands on the four top layers of data representation, semantics, pragmatics and trust from the pyramid graphic in my previous climbing the data federation pyramid post. (Also, note that Ian Horrocks et al. have updated this “stack” and looked at it from the basis of current standards, including OWL and inclusion of encryption.[4])
The foundation of the “stack” is Unicode, an industry standard for digital representation of human languages, symbols and scripts, and URIs (uniform resource identifiers), which, like URLs, provide a unique and unambiguous basis for locating resources.
The next layer, as in the data federation pyramid, is XML.
The basic enabler for semantic representation comes from the next RDF + Schema layer. RDF (resource description framework) is a first-order description logic “triple” representation of subject – predicate – object. The subjects and objects are nouns or “things” with the subject needing to be described via a URI (optional for the object). The predicate is a verb that describes the relationship between subject and object, and is often expressed in syntax such as isPartof or hasSex or hasBirthplace, etc. In terms of graph theory, RDF is a directed graph where the subjects and objects are nodes and the predicate is an edge. RDF Schema extends the RDF “triple” by adding semantics that relate domains, relationships and subclasses and subproperties. RDF Schema provides very wide nteroperability, but it is minimalist and unable to capture a complete semantic logic.
The ontology layer provides more “meta” information, such as transitive, unique, unambiguous, cardinality or other properties. Based on RDF, ontology languages provide a means for conveying domain representations or “world views” electronically for machine processing. Today, the standard is OWL (Web ontology language), which grew out of the earlier OIL (EU) and DAML (US) incipient standards. (However, any internally consistent syntax and language for descriptive logic can also qualify as an ontology layer.) In OWL, there are also three levels — or sub-languages — cardinality. OWL DL is a computationally complete description logic (all statements can be computed and will finish in finite time). OWL Full provides the syntactic freedom of RDF with no computational guarantees. OWL Full may be necessary for a complete representation of an ontolological domain, even though it cannot be guaranteed to be internally consistent. Each of these sublanguages is an extension of its simpler predecessor.
Of course, the real rub arises when different world views need to be reconciled, or what is known as semantic mediation. In this instance, it is now necessary to invoke reconciliation logic. (Is my “glad” your “happy”? Are my countries expressed as two-letter acronyms and yours spelled out in French, and do yours include native lands in addition to nation-states?)
(In fact, the next posting in this series actually details about 40 different sources of semantic heterogeneity.)
So, even if multiple domain specifications are provided via OWL, federating them requires mediating these heterogeneities, and that requires some form of logic or rule-based expert system. Thus, in terms of standards, we have achieved the representational ways to express semantics, but the logics and rules for resolving them are open and not likely subject to standards. (Indeed, most view the semantic mediation step at best as lending itself to semi-automatic methods.)
Finally, the ‘birthday cake’ shows that even with logics in place to resolve or mediate heterogeneities, the vexing challenge of what information to trust remains, the resolution of which is perhaps aided with digital signatures or certificates.
| NOTE: This posting is part of an occasional series looking at a new category that I and BrightPlanet are terming the eXtensible Semantic Data Model (XSDM). Topics in this series cover all information related to extensible data models and engines applicable to documents, metadata, attributes, semi-structured data, or the processing, storing and indexing of XML, RDF, OWL, or SKOS data. A major white paper will be produced at the conclusion of the series. |
[1] Tim Berners-Lee, James Hendler, and Ora Lassila, “The Semantic Web,” in Scientific American 284(5): pp 34-43, 2001. See http://www.scientificamerican.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21&catID=2.[2] Tim Berners-Lee and Mark Fischetti, Weaving the Web: The Original Design and Ultimate Destiny of the World Wide Web by Its Inventor, Harper, San Francisco, 226 pp., 1999.
[3] Tim Berners-Lee, “Semantic Web on XML,” at XML 2000, December 6, Washington, DC. See http://www.w3.org/2000/Talks/1206-xml2k-tbl
[4] Ian Horrocks, Bijan Parsia, Peter Patel-Schneider, and James Hendler, “Semantic Web Architecture: Stack or Two Towers?,” in Francois Fages and Sylvain Soliman, editors, Principles and Practice of Semantic Web Reasoning (PPSWR 2005), No. 3703 in LNCS, pp 37-41, 2005. See http://www.cs.man.ac.uk/~horrocks/Publications/download/2005/HPPH05.pdf.
