





In earlier posts, I described the significant progress in climbing the data federation pyramid, today’s evolution in emphasis to the semantic Web, and the 40 or so sources of semantic heterogeneity. We now transition to an overview of how one goes about providing these semantics and resolving these heterogeneities.
Why the Need for Tools and Automation?
In an excellent recent overview of semantic Web progress, Paul Warren points out:[1]
Although knowledge workers no doubt believe in the value of annotating their documents, the pressure to create metadata isn’t present. In fact, the pressure of time will work in a counter direction. Annotation’s benefits accrue to other workers; the knowledge creator only benefits if a community of knowledge workers abides by the same rules. . . . Developing semiautomatic tools for learning ontologies and extracting metadata is a key research area . . . .Having to move out of a user’s typical working environment to ‘do knowledge management’ will act as a disincentive, whether the user is creating or retrieving knowledge.
Of course, even assuming that ontologies are created and semantics and metadata are added to content, there still remains the nasty problems of resolving heterogeneities (semantic mediation) and efficiently storing and retrieving the metadata and semantic relationships.
Putting all of this process in place requires the infrastructure in the form of tools and automation and proper incentives and rewards for users and suppliers to conform to it.
Areas Requiring Tools and Automation
In his paper, Warren repeatedly points to the need for “semi-automatic” methods to make the semantic Web a reality. He makes fully a dozen such references, in addition to multiple references to the need for “reasoning algorithms.” In any case, here are some of the areas noted by Warren needing “semi-automatic” methods:
- Assign authoritativeness
- Learn ontologies
- Infer better search requests
- Mediate ontologies (semantic resolution)
- Support visualization
- Assign collaborations
- Infer relationships
- Extract entities
- Create ontologies
- Maintain and evolve ontologies
- Create taxonomies
- Infer trust
- Analyze links
- etc.
In a different vein, SemWebCentral lists these clusters of semantic Web-related tasks, each of which also requires tools:[2]
- Create an ontology — use a text or graphical ontology editor to create the ontology, which is then validated. The resulting ontology can then be viewed with a browser before being published
- Disambiguate data — generate a mapping between multiple ontologies to identify where classes and properties are the same
- Expose a relational database as OWL — an editor is first used to create the ontologies that represent the database schema, then the ontologies are validated, translated to OWL and then the generated OWL is validated
- Intelligently query distributed data — repository and again able to be queried
- Manually create data from an ontology — a user would use an editor to create new OWL data based on existing ontologies, which is then validated and browsable
- Programmatically interact with OWL content — custom programs can view, create, and modify OWL content with an API
- Query non-OWL data — via an annotation tool, create OWL metadata from non-OWL content
- Visualize semantic data — view semantic data in a custom visualizer.
With some ontologies approaching tens to hundreds of thousands to millions of triples, viewing, annotating and reconciling at scale can be daunting tasks, the efforts behind which would never be taken without useful tools and automation.
A Workflow Perspective Helps Frame the Challenge
A 2005 paper by Izza, Vincent and Burlat (among many other excellent ones) at the first International Conference on Interoperability of Enterprise Software and Applications (INTEROP-ESA) provides a very readable overview on the role of semantics and ontologies in enterprise integration.[3] Besides proposing a fairly compelling unified framework, the authors also present a useful workflow perspective emphasizing Web services (WS), also applicable to semantics in general, that helps frame this challenge:
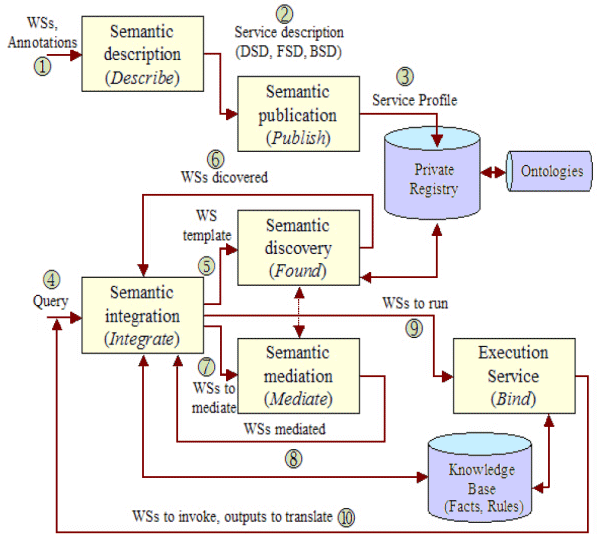
Generic Semantic Integration Workflow (adapted from [3])
For existing data and documents, the workflow begins with information extraction or annotation of semantics and metadata (#1) in accordance with a reference ontology. Newly found information via harvesting must also be integrated; however, external information or services may come bearing their own ontologies, in which case some form of semantic mediation is required.
Of course, this is a generic workflow, and depending on the interoperation task, different flows and steps may be required. Indeed, the overall workflow can vary by perspective and researcher, with semantic resolution workflow modeling a prime area of current investigations. (As one alternative among scores, see for example Cardoso and Sheth.[4])
Matching and Mapping Semantic Heterogeneities
Semantic mediation is a process of matching schemas and mapping attributes and values, often with intermediate transformations (such as unit or language conversions) also required. The general problem of schema integration is not new, with one prior reference going back as early as 1986. [5] According to Alon Halevy:[6]
As would be expected, people have tried building semi-automated schema-matching systems by employing a variety of heuristics. The process of reconciling semantic heterogeneity typically involves two steps. In the first, called schema matching, we find correspondences between pairs (or larger sets) of elements of the two schemas that refer to the same concepts or objects in the real world. In the second step, we build on these correspondences to create the actual schema mapping expressions.
The issues of matching and mapping have been addressed in many tools, notably commercial ones from MetaMatrix,[7] and open source and academic projects such as Piazza, [8] SIMILE, [9] and the WSMX (Web service modeling execution environment) protocol from DERI. [10] [11] A superb description of the challenges in reconciling the vocabularies of different data sources is also found in the thesis by Dr. AnHai Doan, which won the 2003 ACM’s Prestigious Doctoral Dissertation Award.[12]
What all of these efforts has found is the inability to completely automate the mediation process. The current state-of-the-art is to reconcile what is largely unambiguous automatically, and then prompt analysts or subject matter experts to decide the questionable matches. These are known as “semi-automated” systems and the user interface and data presentation and workflow become as important as the underlying matching and mapping algorithms. According to the WSMX project, there is always a trade-off between how accurate these mappings are and the degree of automation that can be offered.
Also a Need for Efficient Semantic Data Stores
Once all of these reconciliations take place there is the (often undiscussed) need to index, store and retrieve these semantics and their relationships at scale, particularly for enterprise deployments. This is a topic I have addressed many times from the standpoint of scalability, more scalability, and comparisons of database and relational technologies, but it is also not a new topic in the general community.
As Stonebraker and Hellerstein note in their retrospective covering 35 years of development in databases,[13] some of the first post-relational data models were typically called semantic data models, including those of Smith and Smith in 1977[14] and Hammer and McLeod in 1981.[15] Perhaps what is different now is our ability to address some of the fundamental issues.
At any rate, this subsection is included here because of the hidden importance of database foundations. It is therefore a topic often addressed in this series.
A Partial Listing of Semantic Web Tools
In all of these areas, there is a growing, but still spotty, set of tools for conducting these semantic tasks. SemWebCentral, the open source tools resource center, for example, lists many tools and whether they interact or not with one another (the general answer is often No).[16] Protégé also has a fairly long list of plugins, but not unfortunately well organized. [17]
In the table below, I begin to compile a partial listing of semantic Web tools, with more than 50 listed. Though a few are commercial, most are open source. Also, for the open source tools, only the most prominent ones are listed (Sourceforge, for example, has about 200 projects listed with some relation to the semantic Web though most of minor or not yet in alpha release).
|
NAME |
URL |
DESCRIPTION |
| Almo | http://ontoware.org/projects/almo | An ontology-based workflow engine in Java |
| Altova SemanticWorks | http://www.altova.com/products_semanticworks.html | Visual RDF and OWL editor that auto-generates RDF/XML or nTriples based on visual ontology design |
| Bibster | http://bibster.semanticweb.org/ | A semantics-based bibliographic peer-to-peer system |
| cwm | http://www.w3.org/2000/10/swap/doc/cwm.html | A general purpose data processor for the semantic Web |
| Deep Query Manager | http://www.brightplanet.com/products/dqm_overview.asp | Search federator from deep Web sources |
| DOSE | https://sourceforge.net/projects/dose | A distributed platform for semantic annotation |
| ekoss.org | http://www.ekoss.org/ | A collaborative knowledge sharing environment where model developers can submit advertisements |
| Endeca | http://www.endeca.com | Facet-based content organizer and search platform |
| FOAM | http://ontoware.org/projects/map | Framework for ontology alignment and mapping |
| Gnowsis | http://www.gnowsis.org/ | A semantic desktop environment |
| GrOWL | http://ecoinformatics.uvm.edu/technologies/growl-knowledge-modeler.html | Open source graphical ontology browser and editor |
| HAWK | http://swat.cse.lehigh.edu/projects/index.html#hawk | OWL repository framework and toolkit |
| HELENOS | http://ontoware.org/projects/artemis | A Knowledge discovery workbench for the semantic Web |
| Jambalaya | http://www.thechiselgroup.org/jambalaya | Protégé plug-in for visualizing ontologies |
| Jastor | http://jastor.sourceforge.net/ | Open source Java code generator that emits Java Beans from ontologies |
| Jena | http://jena.sourceforge.net/ | Opensource ontology API written in Java |
| KAON | http://kaon.semanticweb.org/ | Open source ontology management infrastructure |
| Kazuki | http://projects.semwebcentral.org/projects/kazuki/ | Generates a java API for working with OWL instance data directly from a set of OWL ontologies |
| Kowari | http://www.kowari.org/ | Open source database for RDF and OWL |
| LuMriX | http://www.lumrix.net/xmlsearch.php | A commercial search engine using semantic Web technologies |
| MetaMatrix | http://www.metamatrix.com/ | Semantic vocabulary mediation and other tools |
| Metatomix | http://www.metatomix.com/ | Commercial semantic toolkits and editors |
| MindRaider | http://mindraider.sourceforge.net/index.html | Open source semantic Web outline editor |
| Model Futures OWL Editor | http://www.modelfutures.com/OwlEditor.html | Simple OWL tools, featuring UML (XMI), ErWin, thesaurus and imports |
| Net OWL | http://www.netowl.com/ | Entity extraction engine from SRA International |
| Nokia Semantic Web Server | https://sourceforge.net/projects/sws-uriqa | An RDF based knowledge portal for publishing both authoritative and third party descriptions of URI denoted resources |
| OntoEdit/OntoStudio | http://ontoedit.com/ | Engineering environment for ontologies |
| OntoMat Annotizer | http://annotation.semanticweb.org/ontomat | Interactive Web page OWL and semantic annotator tool |
| Oyster | http://ontoware.org/projects/oyster | Peer-to-peer system for storing and sharing ontology metadata |
| Piggy Bank | http://simile.mit.edu/piggy-bank/ | A Firefox-based semantic Web browser |
| Pike | http://pike.ida.liu.se/ | A dynamic programming (scripting) language similar to Java and C for the semantic Web |
| pOWL | http://powl.sourceforge.net/index.php | Semantic Web development platform |
| Protégé | http://protege.stanford.edu/ | Open source visual ontology editor written in Java with many plug-in tools |
| RACER Project | https://sourceforge.net/projects/racerproject | A collection of Projects and Tools to be used with the semantic reasoning engine RacerPro |
| RDFReactor | http://rdfreactor.ontoware.org/ | Access RDF from Java using inferencing |
| Redland | http://librdf.org/ | Open source software libraries supporting RDF |
| RelationalOWL | https://sourceforge.net/projects/relational-owl | Automatically extracts the semantics of virtually any relational database and transforms this information automatically into RDF/OW |
| Semantical | http://semantical.org/ | Open source semantic Web search engine |
| SemanticWorks | http://www.altova.com/products_semanticworks.html | SemanticWorks RDF/OWL Editor |
| Semantic Mediawiki | https://sourceforge.net/projects/semediawiki | Semantic extension to the MediaWiiki wiki |
| Semantic Net Generator | https://sourceforge.net/projects/semantag | Utility for generating topic maps automatically |
| Sesame | http://www.openrdf.org/ | An open source RDF database with support for RDF Schema inferencing and querying |
| SMART | http://web.ict.nsc.ru/smart/index.phtml?lang=en | System for Managing Applications based on RDF Technology |
| SMORE | http://www.mindswap.org/2005/SMORE/ | OWL markup for HTML pages |
| SPARQL | http://www.w3.org/TR/rdf-sparql-query/ | Query language for RDF |
| SWCLOS | http://iswc2004.semanticweb.org/demos/32/ | A semantic Web processor using Lisp |
| Swoogle | http://swoogle.umbc.edu/ | A semantic Web search engine with 1.5 M resources |
| SWOOP | http://www.mindswap.org/2004/SWOOP/ | A lightweight ontology editor |
| Turtle | http://www.ilrt.bris.ac.uk/discovery/2004/01/turtle/ | Terse RDF “Triple” language |
| WSMO Studio | https://sourceforge.net/projects/wsmostudio | A semantic Web service editor compliant with WSMO as a set of Eclipse plug-ins |
| WSMT Toolkit | https://sourceforge.net/projects/wsmt | The Web Service Modeling Toolkit (WSMT) is a collection of tools for use with the Web Service Modeling Ontology (WSMO), the Web Service Modeling Language (WSML) and the Web Service Execution Environment (WSMX) |
| WSMX | https://sourceforge.net/projects/wsmx/ | Execution environment for dynamic use of semantic Web services |
Tools Still Crude, Integration Not Compelling
Individually, there are some impressive and capable tools on this list. Generally, however, the interfaces are not intuitive, integration between tools is lacking, and why and how standard analysts should embrace them is lacking. In the semantic Web, we have yet to see an application of the magnitude of the first Mosaic browser that made HTML and the World Wide Web compelling.
It is perhaps likely that a similar “killer app” may not be forthcoming for the semantic Web. But it is important to remember just how entwined tools are to accelerating acceptance and growth of new standards and protocols.
 This Friday brown bag leftover was first placed into the AI3 refrigerator about four years ago on June 12, 2006. It was the follow-on to last week’s Brown Bag Lunch posting. It is also the first attempt I made at assembling semantic Web- and -related tools, which has now grown into the 800+ Sweet Tools listing. No changes have been made to the original posting.
This Friday brown bag leftover was first placed into the AI3 refrigerator about four years ago on June 12, 2006. It was the follow-on to last week’s Brown Bag Lunch posting. It is also the first attempt I made at assembling semantic Web- and -related tools, which has now grown into the 800+ Sweet Tools listing. No changes have been made to the original posting.
Kowari is now called Mulgara and the project is hosted on http://www.mulgara.org