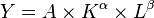Unpacking the Growth-producing Factors of Production
Unpacking the Growth-producing Factors of Production
In my last article on artificial intelligence, I made the statement that “. . . innovation is the source of wealth creation.” I made that unquestioned statement as part of my reflexive world view. But, when I re-read the article after its posting, I asked myself: What are the actual arguments and evidence for this innovation-to-wealth assertion? Surprisingly, there is not nearly the evidential basis for this assertion that I would have assumed.
Since Adam Smith, the signal focus of economics has been its attempt to explain the basis of growth. This is not surprising since the birth of the field of economics also corresponded to an historically unprecedented inflection point in economic growth (see next). Smith ascribed this source to productivity resulting from the division of labor using his famous example of the pin factory. But it is really only within the past fifty years or so that economists have begun unpacking the growth function from the other factors of production.
Growth is a percent increase from a prior state. In economic terms, growth compounded over a period of time has the virtuous reward of resulting in increased wealth. Economic growth is often measured through such means as revenues (for the individual firm) or GDP (for regions or countries). Net worth (for the firm) or GDP per capita or net worth (for individuals) measure the wealth associated with the current stock of economic goods at any given point in time. And, of course, wealth alone also masks the importance of changes in comfort, convenience, freedom, choice, leisure, mobility and other values that may accompany growth and transcend the material. Too, some “externalities” of economic growth may be negative, such as congestion or pollution, but it is also true that wealthier societies tend to regulate against these effects.
Not only have we seen discontinuities in growth (and then wealth) throughout history, but we see them today between individuals, firms, industries, cities, regions and nations. Unpacking the economic factors of production that lead to growth thus has immense importance across the entire economic spectrum — from individuals to nations. Explicating and then managing these factors are intuitively a basis for improving the welfare of any economic actor. Unlocking the nature of growth, or better understanding that nature, should aid in helping to promote still further growth and wealth. Though questions of distribution and fairness may remain, a rising tide lifts all boats.
Thus, understanding the basis of growth, sustained over time, leading to greater wealth for individuals or nations, is the central question facing economics. And, as we see below, that understanding in turn is intimately related to the importance of information and innovation.
The Common Sense Argument
If we toil, year by year, doing the same activity, like growing wheat, and we gain the same harvest for the same labor and land and inputs, that is what we expect. Yet sometimes, the weather or rainfall patterns may differ, or we may have more children helping us in the fields, or a mule to help plow. Money helps us buy more of the important inputs, maybe more land, more mules or the comfort to have more children. These are the traditional factors of production: that is, land, capital and labor.
If we add more of these factors to the mix, we still understand we have merely tweaked the standard basis of our wheat production. Differences in the amount of these factors of production, throughout most of human history, are what accounted for the differences between rich and poor, landlord and serf. If, by virtue of having more land or children, we are now able to feed more people, we are by first definitions more wealthy, and if we can accumulate more of this wealth, we can leverage these standard factors even more. When we can keep more of what we produce we become more wealthy. Control and exploitation have been logical paths to much wealth creation.
These factors are pretty easy to observe and track. We intuitively understand that more inputs of labor, land or capital can themselves result in growth, but a growth that feels and appears rather fixed based on the change in these inputs. This kind of growth has a more-or-less trending return based on changes in these inputs. These types of inputs may also be subject to diminishing returns, wherein adding more of a given factor produces diminishing or negative payoff. For example, adding more fertilizer to the wheat crop produces less per unit output yield after some optimum, and then can actually reduce yields by burning the crop. Or, while a computer increases the productivity of an individual worker, giving her more computers may actually degrade her overall performance.
But there is also clearly a different kind of growth that is not constrained to a fixed or declining return based on inputs. Perhaps we have a neighbor that raises more wheat, possibly on drier, more marginal land, or with less water or fertilizer. His yield exceeds our own. These differences occur because our neighbor is doing something different and is producing more given his inputs.
Innovation is an individual affair in its discovery, but a communal one in its application. (At which point it is known as information.) Better ways of planting or spacing the wheat, perhaps using a plow, or selecting certain wheat strains for next year’s plantings, or irrigating the land, or providing harnesses to the mules, or dividing and specializing the responsibilities amongst the children, can result in real differences in how much gets harvested for a “similar” set of inputs. And, what I initially innovate, becomes information for the next farmer to emulate. Some of these innovations are new devices, such as harnesses or plows. Some of these innovations are new practices, such as tilling or irrigation methods or specializations in tasks or labor. And, of course, not every farmer must innovate on his own. Copying and imitation diffuse these changes across farms and workers.
Truly, for millenia, this is how human progress took place. Some innovations, such as fire, the wheel, iron and bronze, the arch, alphabets, the plow and the yoke had material benefits to all who encountered them. These innovations were fundamental and diffused at the pace of human movement. But, one could argue, each was understood to be a flash of insight, and not a product of systemic information and process. Further, innovations tended to diffuse slowly, along the pace and concentration of trade routes. The innovative event was quite rare, and most practices had been stable for centuries. It is not at all surprising that early economic ideas tended to focus on the traditional factors of production of land, labor and capital. These had been the steady constants for what had been very slow growth for centuries.
But then a real discontinuity in economic growth compared to all previous recorded history occurred in the early 1800s. Historically flat income averages skyrocketed, as this famous figure showing global changes in per capita (person) GDP from Angus Maddison illustrates [1].
William Nordhaus has captured a similar discontinuity looking at the price of light, normalized according to the labor effort needed to obtain 1000 lumens of light. It, too, shows an exponential decrease in the price of lighting beginning about 1800 [2]:
These comparatively abrupt changes in growth rates, and concomitant changes in wealth, that were orders of magnitude higher than what had been experienced before in human history, garnered the attention of economists and economic historians as never before [3].
From the beginning, this difference in growth rates was largely attributed to “technological change”, but the specific causes of this change have been ascribed to many things. The close concurrency to the Enlightenment suggested some fundamental change in thinking. Similarly, the concurrence with the Industrial Revolution suggested the importance of machines, prime movers and the harnessing of energy. Cultural and religious factors have been posited to explain why Britain and then the United States were the initial centers of growth. The invisible hand of the market and division of labor and specialization were advocated by Adam Smith. I have argued the importance of the mechanical printing press and pulp paper in bringing information to a broader swathe of society [3]. Education and support for basic and applied research have their advocates. Financial and banking innovations, and the rule of law and patents and other intellectual property rights, have also been cited as causes.
Common sense tells us that all of these factors, and perhaps more, can all work as force multipliers to the traditional inputs to the economic function.
But, until the mid-1950s, the broad sense of “technological change” and vague causative factors were more often than not argued in an anecdotal, literary way. Empirical datasets were few and far between to test hypotheses, and quantitative means of reasoning over economic problems were only just beginning. Economic growth theory was only just beginning to be an economic discipline in its own right.
The Theoretical Arguments
Joseph Schumpeter, in The Theory of Economic Development, first published in 1911, argued that innovation was central to economic growth and constantly disrupted the general equilibrium of market exchange [4]. Innovation granted the firm a temporary monopoly status in which to charge higher rents, thereby providing an incentive for further innovation. Schumpeter’s emphasis on entrepreneurialship and his popularization of “creative destruction” recognized that new innovative market entrants may cause older firms to become obsolete. He tied these ideas into his basic views on business cycles, also driven by technological change. Innovation was central to Schumpeter’s economic world view.
But the theoretical story really begins in earnest after World War II when the hidden X factor of technological change — in what came to be expressed as total factor productivity — came to the fore to complete the economic growth equation [5].
The Exogenous Model
Robert Solow is an American economist particularly known for his work on the theory of economic growth; the exogenous growth model is named after his work. Solow took courses from Schumpeter at Harvard and was influenced by his views on innovation and technological change [6], though Solow was also part of the generation of economists embracing the new discipline of mathematical or quantitative economics, which was foreign to Schumpeter.
As noted, economic growth was known to go beyond the typical factors of production. Solow’s insight in two papers in 1956 and 1957, for which he won a Nobel prize, was that technological change, what he called “technological progress,” must be the “residual” left over from empirical growth once the traditional inputs of labor and capital are removed [7]. Using his model, Solow calculated that about 87.5% of the growth in US output per worker was attributable to technical progress [8]. A substitute term is total-factor productivity (TFP), the “residual” in total output not credited to the traditional inputs of labor and capital. By definition, TFP cannot be measured directly.
We can express this mathematically as showing total output (Y) as a function of total-factor productivity (A), capital input (K), labor input (L), and the two inputs’ respective shares of output (α and β are the capital input share of contribution for K and L respectively):
These considerations make the exogenous growth model one of the neo-classical growth models, wherein the long-run rate of growth is exogenously supplied, apart from the internal growths of labor and capital. Within this camp, one explanation is based on the savings rate (the Harrod–Domar model); the other, as shown herein, is the rate of technological progress (Solow-Swan model [7]). By definition, in either of these so-called neo-classical models, the savings rate or the rate of technological progress remains unexplained. They are abstract external forces that are just “out there.”
The TFP approach remains strong as a basis for estimating total non-traditional inputs to the production function. It also provides a specific target within quantitative economics to begin addressing explicitly a placeholder for innovation, technological change, information, or other non-traditional considerations for what constitutes the overall production function. But, frankly, TFP still is a blob that needs to be unpacked and teased apart.
The Endogenous Model
A seminal paper by Kenneth Arrow in 1962 paper introduced the concept and evidence for what he called “learning by doing“; what is now more formally understood and accepted as the learning curve. Unlike a specific innovation, the idea of the learning curve captured that experience and practice led to efficiencies and productivity. In other words, more whatever could be done with less what as we learn better how to do whatever.
By the 1960s and 1970s it was becoming clear that developed economies were becoming information economies, increasingly staffed by knowledge workers, and these forces needed to be made explicit within quantitative models. Robert Lucas, now a Nobel laureate from the University of Chicago, probed the questions of rational expectations and internal factors promoting growth. By the mid-1980s, a group of growth theorists had became increasingly dissatisfied with common accounts of exogenous factors determining long-run growth. The focus shifted to the needs for quantitative models that made these “technological” or “information” factors explicit. In other words, these “X” factors needed to be moved from a lump, external consideration to an internal one within the models, with their own multipliers and feedbacks. In short, these new growth factors needed to be made endogenous (internal), not exogenous (external).
A book by David Warsh in 2007, Knowledge and the Wealth of Nations: A Story of Economic Discovery, is a comprehensive explanation of this transition, with a focus on Paul Romer, then of Stanford University, but earlier a colleague of Lucas, pivoting on his seminal paper, “Endogenous Technological Change” [9]. By bringing the consideration internal to the model, it could be groped, inspected and broken into parts.
Besides this essential change in focus, this and related Romer papers also brought two further key insights. First, information and its artifacts are also products and outputs of the economic function. And, second, once produced, many information or knowledge assets may be produced or distributed at essentially zero marginal cost. A new dimension in “rival” and “non-rival” goods had been added to the growth theory lexicon. Information and knowledge themselves were becoming both inputs and outputs to the economic function. This understanding required still further unpacking.
Refining Inputs and Parameters
As a non-economist, it seems a bit perplexing to me how long it took the discipline to start explicating and unpacking the factors of economic growth [10]. To be fair, most every domain of human inquiry has suffered from lacking essential test datasets and statistics upon which to probe and test assumptions. There is perhaps no better poster child for this lack of reference datasets than what has been necessary to test and probe the questions related to economic growth. Yet, as our intro suggested, there is also perhaps no more important area of human inquiry than to understand these non-traditional factors of economic growth. Better understanding of these factors will impact all economic actors from individuals to firms to nations.
Our first approximation must be to get to common units and denominators that enable calculation and comparison. Things like GDP, for example, need to be re-expressed as per capita figures to take out general population growth; money terms need to be expressed in real dollars (or whatever currency), perhaps even further adjusted to account for differences in assumed deflators and inflators across metrics. We’re getting smart enough about this stuff that we can now apply best practices for common data comparisons.
Even the traditional factors of production need further attention. Let’s first take the concept of labor. Labor is ubiquitous in virtually all economic calculations.
Most economic datasets compare items across space and time. A simple labor adjustment to per capita or hours worked can mask these underlying structural changes: life expectancy of the workers; male-female participation in the workforce; hours worked per week; holidays and vacation time; changes in retirement ages; general population and cohort growth; and, then and only then, labor productivity. Of course, the reasons for labor productivity itself come back to innovation and information: the use of better machines, practices and methods by which we do our tasks.
Similarly, the idea of “human capital” has also become predominate in the economic growth literature. Is human capital a subset of general capital? labor? Does human capital include education, training, experience, intellectual capabilitiies, etc.? And, if so, how can these be measured and made consistent for comparison or decision purposes?
We also see that the nature of innovation, information, knowledge, intellectual property (IP), practices, information artifacts, and the like, lack any consistency as to definitions and boundaries. How can nebulous concepts be compared to still other nebulous concepts in order to draw meaningful conclusons? How can test datasets be created to refine these questions if the basic concepts and definitions remain ambiguous?
We see, for example, that knowledge and its role in economic growth may vary as to whether the knowledge is propositional (the ‘sciences’), prescriptive (‘recipes’), a discovery, or an invention [10]. These may not be the best splits, but clearly we must be able to distinguish at minimum innovative ‘aha!s’ from the tech transfer of best practices. These are fundamentally different notions of information. And, of course, none of this discussion directly addresses the internal controversy within the economics community of information v knowledge.
Once we normalize our traditional inputs to the economic function to appropriate per unit bases expressed in constant, real dollars, the residual “total factor productivity” is all due to innovation and information. Innovation is the spark that brings us new methods and devices for doing things, as eventually disseminated throughout the economy via the diffusion of information. Since innovation is itself based on information, we can truly say that information is the fount from which all per capita growth and wealth ultimately derives.
The Empirical Argument
In a recent paper on total factor productivity going back 150 years to the Civil War, researchers from the Congressional Budget Office have calculated that private-sector nonfarm TFP in the United States grew at an average rate of roughly 1.6 percent to 1.8 percent annually, but has experienced several surges occurring in varying parts of the economy [11].
On a different basis, I have used Robert Schiller’s published data on per capita GDP going back to 1900 to show a similar growth trend [12]. The trendline from this data series shows an annual compounded growth rate of about 1.84% per year:
These kinds of growth rates imply a doubling of wealth every 40 to 45 years.
When TFP was first being formulated, Solow calculated that 87.5% of the growth in US output per worker was attributable to technical progress [8]. In 1954, Solomon Fabricant estimated 90% of growth was due to technological factors [13]. But, as we have seen, these were “lumpy” measures and factors like the changing size and composition of the work force (especially the growth of women and two-earner families) also masked other changes.
A different way to approximate the role of technological progress is to look at the market measure of the US markets. Again using Schiller’s CAPE data [12], but also now adjusted to a per capita basis (for the US, [14]), we see the following trends since 1900:
Nominally, labor is removed from this equation because it has been accounted for as an expense on the firm’s books. Similarly, the return due to capital has been accounted for via the payout of dividends. Under these bases, we see that the growth in value of large US firms — despite the severe oscillations due to market cycles — has been a bit more than 1 per cent per annum compounded. This would suggest that the combination of innovation and information accounted for about 55 percent of the overall per capital GDP growth rate noted earlier.
But this proxy is itself flawed in many ways. First, the S&P index is for only the 500 largest US firms, which are certainly not representative. Also, comparing GDP and S&P figures hides the fact that much of the growth and productivity of US firms occurs via foreign subsidiaries. Also, of course, labor and capital productivity — themselves the result of innovation and information — are also taken out of the S&P estimates. The discrepancy between TFP estimates as a source of growth and intrinsic S&P valuation growth is in part explained by this different accounting metric. But the real issue in all of these proxies is that we are not yet fully unpacking the various sources of information and innovation as the drivers of underlying growth.
Only within the last few years have we begun to assemble the right datasets and account for the right factors in this unpacking of growth factors. For example, between 2000 and 2005, estimates at the industry level indicate that almost half of aggregate productivity was due to productivity growth originating from information technology [15], though the IT industries themselves only accounted for a little over 3% of nominal aggregate value [16].
These findings are from a more detailed analysis of productivity and growth by Jorgenson, Ho and Samuels [16]. Their analysis attempted to explicitly separate out innovation from the diffusion of prior innovations due to information. In the authors’ words:
“We show that the great preponderance of economic growth in the US since 1947 involves the replication of existing technologies through investment in equipment, structures, and software and expansion of the labor force. Contrary to the well-known views of Robert Solow (1957) and Simon Kuznets (1971), innovation accounts for only about twenty percent of US economic growth. This is the most important empirical finding from the recent research on productivity measurement surveyed by Jorgenson (2009). “
I think some of these differences are due to semantics and terminology. Remember, early residuals and TFP discussions were centered around the concept of “technological progress”. What Schumpeter referred to as “innovation” is now understood to be too broad; innovation is but a part of the overall growth effect due to information. What is helpful from these more recent studies is to separate out innovation from information dissemination. The next step, for which we have not yet developed useful datasets, would be to unpack the ideas of innovation and information into the categories from Mokyr [10]. Namely, these are discoveries and inventions (innovation) and the ideas of propositional and prescriptive information first distinguished by Michael Polanyi as tacit knowledge.
The aphorism that we can not understand what we can not measure applies here. To take our understanding of these empirical factors to the next level we will need to refine our concepts and gather defensible data for estimating them. A proper accounting for growth should also likely distinguish transformative innovations (such as the printing press, electricity and computing) from other discoveries and inventions.
The Beautiful Synergy of Innovation and Information
By 2009, Romer and Jones were able to claim that the endogenous growth model had been proven, and they put forward six research questions to look for in the coming 25 years, including the role of human capital, differential growth rates between countries, and accelerated growth [17]. Innovation had finally assumed its central, internal role in understanding growth.
Innovation is the root source of new devices, new technologies, new practices, new methods and new theories. Innovation, in turn, is based upon the foundational substrate of information. As new innovations occur, new information is added to this substrate, all in a virtuous circle.
Markets will rise and fall, and business cycles will gyrate. New businesses and business models will emerge while others are destroyed or whither away. These reflections of animal spirits and uneven (imperfect or wrong) information can never be smoothed. But, the trajectory of growth, fueled by the beautiful synergy of innovation and information, points to an optimistic future.
To be sure, I am not positing a near-term upward trend in the stock markets. In fact, my own personal view is that markets are temporarily oversold, with a higher near-term probability of declines rather than rises. These oscillations are part and parcel of market cycles. My longer-term optimism reflects more fundamental trends.
We are all aware of the explosion of information and content. Today, like the broadening base of information and literacy that I have elsewhere posited as a major factor in the first upward inflection of economic growth in the 1800s [3], we are in the midst of a still newer — and optimistic — inflection point. Digital content and the Internet are bringing information to nearly every human on earth. Assistive technologies are bringing this information to those previously shut out due to disabilities in sight, hearing or mobility. Non-rivalrous goods can be duplicated at essentially zero cost and open source and broad access mean new ventures can be assembled and tested in the marketplace with unprecedented speed at unprecendented lower cost. Innovation is no longer the remit solely of an educated elite, but is available to every thinking person on earth.
These are all harbingers of continued growth and increases in wealth. Sure, ignorance, despotism, fanaticism and prejudice will cause some periods and pockets to be shut off from these trends, but the broad sweep of information and history looks assured.
Innovation, as Schumpeter first posited a century ago, grants the firm a temporary monopolistic advantage. In a time of openness, information growth, and universal access to that information, the winning competitive formula for firms and knowledge workers alike is constant innovation. Though a commitment to innovation leads to a bumpy path, it is an upward one, and most assuredly the path that is on the right side of history.
[1] The historical data were originally developed in three books by Angus Maddison:
Monitoring the World Economy 1820-1992, OECD, Paris 1995; T
he World Economy: A Millennial Perspective, OECD Development Centre, Paris 2001; and
The World Economy: Historical Statistics, OECD Development Centre, Paris 2003. All these contain detailed source notes. Figures for 1820 onwards are annual, wherever possible.
For earlier years, benchmark figures are shown for 1 AD, 1000 AD, 1500, 1600 and 1700. These figures have been updated to 2003 and may be downloaded by spreadsheet from the Groningen Growth and Development Centre (GGDC), a research group of economists and economic historians at the Economics Department of the University of Groningen, headed by Maddison before his passing in 2010. See
http://www.ggdc.net/.
[2] William D. Nordhaus, 1996. “Do Real-Output and Real-Wage Measures Capture Reality? The History of Lighting Suggests Not,” in Timothy F. Bresnahan and Robert J. Gordon, eds., The Economics of New Goods, University of Chicago Press, ISBN: 0-226-07415-3, January 1996, pp. 27 – 70. See
http://www.nber.org/chapters/c6064.
[3] I have addressed these broad topics firstly in,
“Information is the Basis for Economic Growth” (
Adaptive Information blog, AI3, August 23, 2007), and in some book reviews, notably
“Knowledge: Unravelling the X Factor in Growth and Wealth” (
Adaptive Information blog, AI3, June 21, 2006) and
“Historical Origins of the Knowledge Economy” (
Adaptive Information blog, AI3, July 6, 2006).
[7] Solow’s endogenous model of economic growth is also known as the
Solow-Swan neo-classical growth model as the model was independently discovered by
Trevor W. Swan and published in “The Economic Record” in 1956, allows the determinants of economic growth to be separated out into increases in inputs (
labor and capital) and technical progress.
[8] Robert M. Solow, 1957. “Technical Change and the Aggregate Production Function”.
Review of Economics and Statistics (The MIT Press) 39 (3): 312–320.
doi:
10.2307/1926047.
JSTOR 1926047.
[9] Published in the
Journal of Political Economy in 1990.
[10] In 2002 Joel Mokyr, an economic historian from Northwestern University, wrote a book that should be read by anyone interested in knowledge and its role in economic growth.
The Gifts of Athena : Historical Origins of the Knowledge Economy is a sweeping and comprehensive account of the period from 1760 (in what Mokyr calls the “Industrial Enlightenment”) through the Industrial Revolution beginning roughly in 1820 and then continuing through the end of the 19th century.
[12] Stock market and cyclically-adjusted price earnings (CAPE) ratio data from Robert J. Schiller, 2000. Irrational Exuberance, Princeton University Press. Data as periodically updated and available from
http://www.econ.yale.edu/~shiller/data/ie_data.xls.
[13] Solomon fabricant, 1954. “Economic Progress and Economic Change, a part of the 34th annual report of the National Bureau of Economic Research.”
New York.
[17]Charles I. Jones and Paul M. Romer, 2009. “The New Kaldor Facts: Ideas, Institutions, Population, and Human Capital,” Working Paper 15094, National Bureau Of Economic Research, 31 pp, June 2009. See
http://www.nber.org/papers/w15094.





 Technology has Advanced, but the Experience is Much the Same
Technology has Advanced, but the Experience is Much the Same The nexus of my original energy consulting was DC (and other national locations), which caused me to travel up to 150,000 air miles annually during the early years. I literally went through a case of thermal fax paper each month to keep current with my clients and partners. In rural Montana I was quite the anomaly; most of my plane telecommuters were celebrities like Huey Lewis or Andie MacDowell, frequent co-travellers on my flights out of Missoula. Local civic groups often asked me to speak on what it was like to be a telework pioneer. I continued this for nearly five years, when I decided that software trumped straight consulting. By the time of our next move to Vermillion, SD, my transition to software was complete.
The nexus of my original energy consulting was DC (and other national locations), which caused me to travel up to 150,000 air miles annually during the early years. I literally went through a case of thermal fax paper each month to keep current with my clients and partners. In rural Montana I was quite the anomaly; most of my plane telecommuters were celebrities like Huey Lewis or Andie MacDowell, frequent co-travellers on my flights out of Missoula. Local civic groups often asked me to speak on what it was like to be a telework pioneer. I continued this for nearly five years, when I decided that software trumped straight consulting. By the time of our next move to Vermillion, SD, my transition to software was complete. On the expectations front, I knew that I would gain more useful time during the day by avoiding the commute, which was 90 min total for me in DC. What surprised me, however, was the additional time I gained by not needing to keep home and office systems synchronized. Early on, I found I had gained about two hours of time each day in avoiding commuting and coordination activities! Not bad; not bad at all.
On the expectations front, I knew that I would gain more useful time during the day by avoiding the commute, which was 90 min total for me in DC. What surprised me, however, was the additional time I gained by not needing to keep home and office systems synchronized. Early on, I found I had gained about two hours of time each day in avoiding commuting and coordination activities! Not bad; not bad at all. I never eat in my office and do not have a television or other distractions. I try to keep regular hours. I treat my office as such, and keep family and home activities distinct. Through the years the biggest challenge has been to not allow the ease of “going into the office” to take over my life. Frankly, I have not always kept this balance, since I have always loved my work and it is also one of my main hobbies and source of intellectual stimulus.
I never eat in my office and do not have a television or other distractions. I try to keep regular hours. I treat my office as such, and keep family and home activities distinct. Through the years the biggest challenge has been to not allow the ease of “going into the office” to take over my life. Frankly, I have not always kept this balance, since I have always loved my work and it is also one of my main hobbies and source of intellectual stimulus.