





Candidate Structures (?) are Manifest and All Over the Map
![]() Some of my previous postings on the structured Web have covered such items as the nature of data structure (including structured, semi-structured and unstructured data), the 40 or so existing data formalisms on the Web (ranging from standard Web pages through feeds and tags to formal ontologies), and various serialization and extraction formats.
Some of my previous postings on the structured Web have covered such items as the nature of data structure (including structured, semi-structured and unstructured data), the 40 or so existing data formalisms on the Web (ranging from standard Web pages through feeds and tags to formal ontologies), and various serialization and extraction formats.
That there is a huge diversity of data structure and forms on the Web is clear. Yet, even in the face of such complexity, there is the natural human penchant for organizing things. What is surprising is the almost total lack of an overarching model or schema for classifying and organizing these various forms of Web data.
A model to classify data structure on the Web would be useful for helping to find meaningful generalities for accessing and using that data. Such a model would also be useful to help organize and streamline the pathways for processing or converting the data from one source form into another. This latter purpose is essential to data federation or combining data from multiple sources — namely, broadening the current innovation of linked data for RDF to all Web data forms.
In the case of the UMBEL lightweight subject reference structure, such a model or organizational schema would also help guide the characterization of source datasets for meaningful processing and access. Thus, formulating such a model or schema is a central task for completing the core UMBEL ontology.
This Part I posting presents a survey of current practice and terminology, with a specific call to begin a practice of Web informatics. This material leads to a forthcoming Part II, wherein this information is then used to present an updated technical data vocabulary and partial ontology for the technical data model at the center of the UMBEL core.
A Call for a Web Informatics
Considerable work has been done on data warehousing and ETL (extract, transform, load) relations in enterprise information integration (EII) for structured data, as well as in the general area of personal information management (PIM). In these cases, traditional MIME types, enterprise service buses, structured database constructs, and application-specific file formats are the drivers within the various schema.
No such discipline has yet appeared for the broader Internet. But we can learn from these other efforts, as well as match them with conceptually grounded structures from computer science, information theory and informatics.
The concept of informatics appears particularly apropos to the questions of Web data, given the heterogeneity of Web data and its lack of conceptual consensus. The biology and genetics communities faced similar issues a decade or so ago when the discipline of bioinformatics began to take hold. According to Michael Fourman [1]:
The University of Edinburgh called for a Web informatics initiative more than five years ago, an effort that does not appear to have gained a significant toehold. Perhaps the timing was too soon. Just as we saw many founding individuals of the Web and other luminaries call for the establishment of a discipline in Web science about one year ago [2], I think the time is now ripe for us to nominate Web science’s first sub-discipline: Web informatics.
That was not a conclusion I began with as I researched this two-part series. But, as I came to see the lack of conceptual, terminology or theoretical consistency around the questions of data, information and their organizational schema on the Web, I became convinced that some bridging construct could be helpful.
The Web is a reflection of global society with its broad spectrums of pettinesses, high ideals, brilliance, stupidity and good and evil. With respect to data and its representations and schema, there seems to be very strong tribalisms. Passion and advocacies are not likely to go away. Even camps which have stated “higher” purposes for data integration and use — such as the topic maps, microformats and the semantic Web communities (a listing by no means meant to be complete) — naturally have their own prejudices and passions.
Frankly, I personally believe all of this to be well and good and communities should be free to chose their own paths and formalisms. The hope for a discipline of Web informatics, however, is that conceptual frameworks and understandings can be developed such that these data communities can interoperate with a modicum of efficiency. Perhaps one or more innovative university departments will take up the call to help establish the umbrella frameworks for interoperable Web data.
A Hodgepodge of Structures and Formalisms
I will not repeat my earlier posting, but one way to see the scope of these Web data dilemmas is to simply list the 40 or so data structures and formalisms currently extant on the Web:
|
|
|
For more information on any of these, the reader is encouraged to look at my earlier post, especially its references.
This variety also does not yet begin to address the various transmission formats (or serializations) by which such data can be transmitted across the Web (e.g., JSON, XML. etc., etc.) nor varieties of encodings (ASCII, Unicode variants, many historical language ones such as Big 5 for Chinese, etc., etc.).
Of course, there are even multiple variants for the listed formalisms. For example, there are multiple microformats, tens to hundreds of schemas and domain vocabularies, and many other varieties within any single category.
Actually, whether there are 20 (as shown) or 40 or 400 data form variants on the Web is a matter of definition and terminology, the lack of consensus to which means there is no “accurate” understanding for any of this stuff.
A Hodgepodge of Concepts and Terms
The careful reader will have seen my almost interchangeable use of concepts such as schema, formalism, structure, model or format in the above paragraphs. So, well, what is it?
Good question. (That is what everyone answers when they don’t know what to answer — which is true for me.)
The data formalisms listed above, and many others not listed, produce a dizzying array of terms and concepts.
Listed below are more than 300 data-related terms gleaned from current Web practice regarding data type descriptions, data format options, roles of using that data, and many confusing and conflicting “dimensions” by which to describe data on the Web. (Granted, not all are classifactory or structural in nature as the basis for “formalisms” or “models”, but that is also not self-evident solely on the basis of inspection or use of term or concept.)
Please note that most of these terms can be looked up directly and individually on Wikipedia:
| access control administrator Adobe XMP agent annotation annotation proxy APIs application protocols architecture assertion Atom AtomOwl attribute audio author binding bindingType blog bookmark briefcase browsing/viewing calendar callback chat chronology class classification CMS commenter component concept concept map configuration construct content content encoding content type converter crawler creator data access data mapping data model data set data transformation database data format datatype dictionary discovering discovery discussion forum DNS DOAP document document type domain DQL Dublin Core eBidItems ecommerce editor element encoding endpoint entity eRDF excel extracting extraction type extractor feed field file |
file format file system filetype FOAF folksonomy formalism format ftp gallery (photo) gateway Gdata generator graph GraphViz grounding subject GRDDL hAtom hCalendar hCard hResume hReview HTML HTTP iCalendar identifer (or ID) IMAP individual information information resource information set infoset instance interface Internet protocol IPC IRC JDBC LDAP lexicon library link linked data literal mailing list map media media type message message board metadata microformats MIME model moderator module N3QL named graph namespace narrative news NNTP node non-XML notification interface N-triple object ODBC OLE ontology (formal) OpenOffice OpenSearch OPML OWL OWL DL |
OWL Full OWL Lite owner P2P page parsing syntax pattern payload places playlist policy POP3 portal PPT predicate property proposition protocol proxy PS publisher publishing query query language R-DEVICE RDF RDF Schema RDF/XML RDFa RDFizers RDFQ RDF-S RDQ RDQL record register registration registry Relax NG rel-directory rel-nofollow rel-tag representation resource reviewer RPC RPI RQL RSS RTF RXR schema schema type scheme search engine searching semantics semistructured data serialization serializer serializing syntax SeRQL service set SIOC SKOS SMTP SOAP source SPARQL SPARUL spreadsheet SQL |
SQLX SSH still image string structure structured data structured report subject subscriber subscription subtype survey SVG synset syntax table tag tagging taxonomy TCP/IP term text thesaurus timeline topic map transformation type transformation transformer TRiG triple Triplr TRiQL Turtle TXL txt type unstructured data URI URIQA URI scheme URL user user agent validation validator value video view visio visitor vocabulary Webcal WebDAV Web page whois wiki Word WS* (Web services) XBEL Xcerpt XFML XFN xFolk XHTML XML XML Schema XMLA XML-RPC XMPP XOXO XPath XPointer XQuery XSLT XUL |
One frightening aspect of such a terminology hodgepodge is that it is nearly endless. The listing of Internet and Web protocols is huge; the listing of file formats is huge; the listing of data translation and parsing conversions is huge; the listing of concepts is still more huge; you get the picture. Were it even possible to list all terms and acronyms potentially applicable to describing and characterizing Web data in all of its manifestations I suspect the listing above would be much larger.
Hmmm. I’m not sure we’re making any progress here . . . . 🙂
A Brief Survey of Reference Schema and Vocabularies
Acknowledging that no one has yet (foolishly or otherwise) attempted to classify this mess, we can however list some of the intellectual bases from which such a classification or “model” might emerge. Accessing and managing the diversity of Web data is not new; many organizations and entities have needed to tackle a portion of this challenge according to their specific circumstances.
Of course, the UMBEL initiative is a major lens through which these options are viewed. A basic Web informatics would likely begin with these intellectual underpinnings (many surely missed; please let me know!), since each of the survey sources or projects listed alphabetically below represents many hours of effort from many very capable individuals. Also please note that close inspection of most of the entries below will uncover their own data architectures, schema and vocabularies:
- Aperture – is a Java framework for extracting and querying full-text and metadata content from various information systems and file formats, including crawling and bulk retrieval. Aperture is an open source effort. Given its breadth, it is a good candidate for schema and formalism classification. An anticipated formal ontology, however, is apparently being updated via NIE (see below)
- CBD — a concise bounded description is recommended within the context of a resource represented in an RDF graph as a general and broadly optimal unit of specific knowledge about that resource to be utilized by, and/or interchanged between, semantic web agents. Specifically, a CBD is a subgraph consisting of those statements which together constitute a focused body of knowledge about the resource denoted by that particular node. The guidance by Patrick Strickler in this document helps inform the proper ontological design for the resource and service descriptions within UMBEL. See “CBD – Concise Bounded Description,” http://sw.nokia.com/uriqa/CBD.html.
- CDS — Conceptual Data Structures is a lightweight top-level ontology about relations that naturally occur in common knowledge artifacts. It is designed to bridge the gap between unstructured content like informal notes and formal semantics like ontologies by allowing the use of vague semantics and by subsuming arbitrary relation types under more general ones. CDS has been developed in relation to personal information management (PIM) and is itself an outgrowth of the earlier Semantic Web Content Model (SWCM). It is suitable for representing knowledge in various degrees of formalisation in a uniform fashion, allowing gradual elaboration. RDF versions and an API are under development, though not yet released. See Conceptual Data Structures (CDS) — Towards an Ontology for Semi-Formal Articulation of Personal Knowledge, 2006, presented at ICCS2006 for more details.
- DODA — Description of a Data Access (DODA) is a lightweight ontology to describe sources and channels for RDF and simple data access services related to semantic Web applications on the desktop. It describes various data access services on the Web and their semantics. Each data access technology is described in terms of send and receive semantics and related characterization parameters; the ontology, available in OWL Lite, can also be used as a wrapper to WSDL services. From [3].
- DRM — the Data Reference Model is one of the five reference models of the Federal Enterprise Architecture (FEA). The DRM Abstract Model is an interesting one in that it represents a consensus view of very heterogeneous data forms, but with little reference to the Web. Nonetheless, its basic framework is very strong and is a likely key reference for the UMBEL efforts:

[Click for full image]
Formal ontologies of this are also presently being developed (see http://www.osera.gov/owl/2004/11/fea/srm.owl, for example).
- IANA— the IANA (Internet Assigned Numbers Authority) is responsible for the global coordination of the DNS Root, IP addressing, and other Internet protocol resources. It is an excellent source for fundamental terminology definitions and distinctions, especially in RFC 2045.
- ICA-Atom — ICA-Atom is an open-source, archival description application that is currently in development, based on the Reference Model for an Open Archival Information System (OAIS). CCSDS 650.0-B-1, Blue Book, January 2002. Also, see Peter Van Garderen (Fri, December 8th, 2006), The Information Model to End All Information Models; see http://archivemati.ca/2006/12/08/the-information-model-to-end-all-information-models/.
- METS — the Metadata Encoding and Transmission Standard (METS) schema is a standard for encoding descriptive, administrative, and structural metadata regarding objects within a digital library, expressed using the XML schema language of the World Wide Web Consortium. The standard is maintained in the Network Development and MARC Standards Office of the Library of Congress, and is being developed as an initiative of the Digital Library Federation.
- MIME — IANA‘s MIME (Multipurpose Internet Mail Extensions) types; it is also a useful organization of content types (specifically called media-types), organized by application, audio, example, image, message, model, multipart, text and video.
- NIE — as noted on some mailing lists, the Aperture (see above) scheme is moving to the Nepomuk Information Element (NIE) ontology soon. The Nepomuk project is developing one standard, conceptual framework for the semantic desktop. The NIE ontology will govern the incorporation and representation of desktop resources in accordance with a local personal information management ontology (PIMO; see below). There is explicit consideration for things like vCard, vCalendar, email, and other common information formats. Much of this general effort has grown out of the earlier Gnowsis semantic desktop project. An interesting aspect of personal information management is that it is something of a microcosm of similar Web-wide issues. See further http://dev.nepomuk.semanticdesktop.org/repos/trunk/ontologies/nie/htmldocs/nie.html.
- OpenCyc — the first release of OpenCyc occurred in early 2002, a major milestone in the the 20-year Cyc effort. The OpenCyc knowledge base and APIs are available under the Apache License. There are presently about 100,000 users of this open source KB, which has the same ontology as the commercial Cyc, but is limited to about 1 million assertions. An OWL version is also available with an RDF version nearing release. The Cyc Foundation has also been formed to help promote further extensions and development around OpenCyc, including extraction of a possible high-level subject structure similar to UMBEL using external resources such as WordNet, Wikipedia and its internal ontology. This is a definite potential contributor (as would possibly be SUMO, see below, but they have declined participation).
- OpenURL — Version 1.0 of the OpenURL specification (Z39.88) describes a framework application as a networked service environment, in which packages of information are transported over a network. These packages have a description of a referenced resource at their core, and they are transported with the intent of obtaining context-sensitive services pertaining to the referenced resource. See http://www.niso.org/standards/resources/Z39_88_2004.pdf.
- PayGo — the PayGo approach (not so much a specific schema as a broader approach to Web-scale integration) takes as its starting point massive scale and heterogeneity of sources and formats. See further [4]. The paper notes the estimate for 25 million deep Web sites, the extreme heterogeneity of existing sites, the rise of new services such as Google Base and Co-op, and the continued emergence of annotation schemes. These lead to a comparison of integration challenges from the traditional viewpoint, and a PayGo viewpoint advocated by the authors for managing only what is necessary:
| Traditional Data Integration | PayGo Data Integration |
| Mediated schema | Schema clusters |
| Schema mappings | Approximate mappings |
| Structured queries | Keyword queries with query routing |
| Query answering | Heterogeneous result ranking |
- PIMO — the PIMO ontology language is premised around personal information management (PIM) within the context of the user’s desktop. The PIMO language contains a core upper ontology, defining basic classes for things, concepts, resources, persons, etc., but is also meant to be extended and (obviously) personalized given the individual world views of different users. In concept, PIMO and its intent is closest to many of the issues for UMBEL, in that there are many data types and formalisms, global subject and topic possibilities, and the need for interchange, collaboration and Web perspectives. The design of PIMO is well thought out and “global” in its scope and foresightedness. See further PIMO – a PIM Ontology for the Semantic Desktop; PIMO was developed and is being updated by Leo Sauermann, now in context with the Nepomuk semantic desktop efforts. It has a full, RDF draft specification from 2006, apparently near to an updating as part of the Nepomuk effort.
- ramm.x — the RDFa-deployed Multimedia Metadata specification (ramm.x) provides an ontology for describing multimedia and multimedia metadata formats such as MPEG-7, Exif, ID3, etc. The specification is based on RDFa, an embedded RDF syntax for HTML documents. ramm.x is a good candidate source for UMBEL characterizations because of its breadth in format and metadata coverage. The specification is also well prepared.
- SIOC — the Semantically-Interlinked Online Communities Project (SIOC) provides methods for interconnecting discussion methods such as blogs, forums and mailing lists to each other. It consists of the SIOC ontology, an open-standard machine readable format for expressing the information contained both explicitly and implicitly in internet discussion methods, of SIOC metadata producers for a number of popular blogging platforms and content management systems, and of storage and browsing / searching systems for leveraging this SIOC data. It is useful in this context for its organization of Web resources.
- SUMO — this is one among a few upper-level ontologies, also with linkages to mid-level (more subject and instance-oriented) ontologies. Since this project has indicated no further interest in UMBEL, no further characterizations have been made, though the scope and number of entities supporting SUMO warrant its further attention.
- SWCM — the Semantic Web Content Model (SWCM) is intended to represent the actual content of web or desktop resources together with their semantic web meta-data. A N3 definition is available. See further A Semantic Web Content Model and Repository by Max Völkel, in Proceedings of the 3rd International Conference on Semantic Technologies (I-SEMANTICS 2007), September 2007.
- W3C — various related standards and data-oriented activties from the World Wide Web Consortium, with specific emphasis on OWL, RDF, WSDL and XML. These have been extensively discussed in other postings.
- Xcerpt — is not a schema per se, but Xcerpt is a query approach and language that is geared to support multiple RDF-related formats, schema and representations. It has a good organizational approach to data models on the Web, and likely deserves more attention. See further [5].
- XPackage — the eXtensible Package (XPackage) is an group of ontologies for describing resources and their associations as they appear in packages or collections of resources. Specification for MIME type, file types, use of ontologies, namespaces, etc., are presented, with RDF versions available. The specification has been in draft for a number of years with a lengthy hiatus; no one appears to be using it.
- XTM — Topic Maps are a major conceptual and organizing focus for federated data, with longstanding development and backing from the Eurpoean Union and OASIS. XTM is a specification for an XML syntax to express and interchange Topic Maps. Though there are significant consistencies with the other major model at an equivalent level, RDF, it is also interesting to look at the contrasts in the two approaches [6] from Lars Marius Garshol:
The two standards families
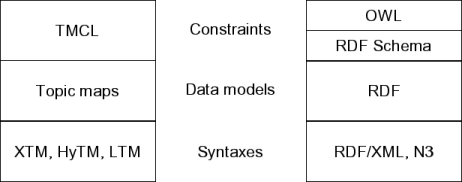
All of the approaches above bring terminology, organization, and structure to the question of Web data. A Web data model that hopes to embrace this diversity of perpsepctives and data use should be familiar at least a cursory level with the objectives and mindsets of each.
A Beginning Vocabulary
Okay, so how does one begin to organize and find common ground in these diverse perspectives? (Which may not be possible across the board!).
The first challenge, I believe, is to find a common vocabulary. While there is inherent structure and organization to concepts, the first step is to ensure all parties are in fact or intent referring to the same thing when they say or write the same term. Getting this agreement is not so easy, and many standards bodies continue to discuss and argue about specific terms even after official “standards” have been adopted.
Indeed, much of the progress of the semantic Web or microformats or whatever community depends on agreeing to what is meant by specific terms or phrases.
Given the broad terminology noted before, the listing below attempts to provide a consistent basis for defining appropriate baseline concepts to a Web data model. Rather than writing my own personal definitions, most of the following are definitions from W3C specifications or recommendations. The two principal sources are the Web Architecture[7] glossary and the Web Services[8] glossary; the remaining listings are drawn from various other W3C glossaries and definitions as presented in the online W3C Glossary[9] service. In addition, some of the definitions have supplementary entries from either wiktionary[10] (using the closest computer-related term where there are multiples) or Wikipedia[11]. Finally, in the case of a few entries, specific other references are invoked.
All source references are listed at the conclusion of this post.
- access control [8] — is protection of resources against unauthorized access; a process by which use of resources is regulated according to a security policy and is permitted by only authorized system entities according to that policy; see further RFC 2828
- agent [8] — is a program acting on behalf of a person or organization, akin to the notion of software agent in [7]
- annotation [9] — is the linking of a new commentary node to an existing node. If readers can annotate nodes, then they can immediately provide feedback if the information is misleading, out of date or plain wrong. Thus the quality of the information in the web can be improved
- API (or application programming interface) [9] — defines how communication may take place between applications. Implementing APIs that are independent of a particular operating environment (as are the W3C DOM Level 2 specifications) may reduce implementation costs for multi-platform user agents and promote the development of multi-platform assistive technologies. Implementing conventional APIs for a particular operating environment may reduce implementation costs for assistive technology developers who wish to interoperate with more than one piece of software running on that operating environment
- architecture [8] — 1. the structure or structures of a software program or computing system. This structure includes software components, the externally visible properties of those components, the relationships among them and the constraints on their use; or 2. an abstraction of the run-time elements of a software system during some phase of its operation. A system may be composed of many levels of abstraction and many phases of operation, each with its own software architecture
- attribute [8] — is a distinct characteristic of an object. An object’s attributes are said to describe the object. Objects’ attributes are often specified in terms of their physical traits, such as size, shape, weight, and color, etc., for real-world objects. Objects in cyberspace might have attributes describing size, type of encoding, network address, etc.
- binding [8] — 1. is an association between an interface, a concrete protocol and a data format. A binding specifies the protocol and data format to be used in transmitting messages defined by the associated interface; or 2. the mapping of an interface and its associated operations to a particular concrete message format and transmission protocol
- class [9] — is a general concept, category or classification; it is something used primarily to classify or categorize other things. Formally, in RDF, it is a resource of type rdfs:Class with an associated set of resources, all of which have the class as a value of the rdf:type property. Classes are often called ‘predicates’ in the formal logical literature
- component [8] — 1. is a software object, meant to interact with other components, encapsulating certain functionality or a set of functionalities. A component has a clearly defined interface and conforms to a prescribed behavior common to all components within an architecture; or 2. is an abstract unit of software instructions and internal state that provides a transformation of data via its interface; or 3. is a unit of architecture with defined boundaries
- concept [9] — is a informal term for the abstractions “in the world” that ontologies describe
- configuration [8] — is a collection of properties which may be changed. A property may influence the behavior of an entity
- content [9] — is the document object as a whole or in parts. If in parts, the content is associated with an element in the source document; not all elements have content in which case they are called empty. The content of an element may include text, and it may include a number of sub-elements, in which case the element is called the parent of those sub-elements
- database [9] — is used vaguely as a term for a collection of nodes . The management information for one of these is kept in one place with all accessible by the same server . Links outside this are “external”, and those inside are “internal”; nothing is implied about how the information should be stored. According to [10], it is a collection of (usually) organized information in a regular structure, usually but not necessarily in a machine-readable format accessed by a computer
- data format [7] — is a specification (for example, for XHTML, RDF/XML, SMIL, XLink, CSS, and PNG) that embodies an agreement on the correct interpretation of representation data
- data model [9] — is a collection of descriptions of data structures and their contained fields, together with the operations or functions that manipulate them. According to [5], it is the structure of the data within a given domain and, by implication, the underlying structure of that domain itself. This means that a data model in fact specifies a dedicated grammar for a dedicated artificial language for that domain.
- data set (or dataset) [9] — is a known grouping of data elements. According to [10], it is a file of related records on a computer-readable medium such as disk
- data type (or datatype) [9] — with specific reference to the XML Schema, it is a 3-tuple, consisting of a) a set of distinct values, called its value space, b) a set of lexical representations, called its lexical space, and c) a set of facets that characterize properties of the value space, individual values or lexical item. These reside in a classification or category of various types of data, that states the possible values that can be taken, how they are stored, and what range of operations are allowed on them, used to qualify both the content and the structure of an element or attribute. According to http://www.en8848.com/Reilly%20Books/xml/schema/gloss.htm, datatypes can be either simple (when they describe an attribute or an element without an embedded element or attribute) or complex (when they describe elements with embedded child elements or attributes)
- dictionary [6] — is a repository containing a definition of the content and structure of a database. It is used by runtime library functions for accessing and manipulating information from that database from
- discovery [8] — is the act of locating a machine-processable description of a Web service-related resource that may have been previously unknown and that meets certain functional criteria. It involves matching a set of functional and other criteria with a set of resource descriptions. The goal is to find an appropriate Web service-related resource
- document [8] — is any data that can be represented in a digital form. [Note: this definition is weak]
- document type [9] — is a class of documents sharing a common abstract structure, which might be expressed as similar characteristics (for example, journal, article, technical manual, or memo), or a formal, machine-readable expression of structure and syntax rules, or schema type or same markup model.
- domain [8] — is an identified set of agents and/or resources that is subject to the constraints of one of more policies. According to [9], it is content supplied in response to a request as a stream of data that, after being combined with any other streams it references, is structured such that it holds information contained within elements. A “document” may be a collection of smaller “documents”, which in turn is a part of a greater “document”
- element [9] — is any identifiable object within a document, for example, a character, word, image, paragraph or spreadsheet cell. In HTML and XML, an element refers to a pair of tags and their content, or an “empty” tag – one that requires no closing tag or content
- encoding [9] — is a mapping from a character set definition to the actual code units used to represent the data, such as such as “UTF-8”, “UTF-16”, or “US-ASCII” (see further the Unicode specification [UNICODE]; also refer to “Character Model for the World Wide Web” [CHARMOD] for additional information about characters and character encodings). According to [10], it is the way in which symbols are mapped onto bytes, e.g., in the rendering of a particular font, or in the mapping from keyboard input into visual text
- end point [8] — is an association between a binding and a network address, specified by a URI, that may be used to communicate with an instance of a service. An end point indicates a specific location for accessing a service using a specific protocol and data format
- entity [9] — is a logical or physical storage unit containing document content. Entities may be composed of markup or character data that can be parsed, or unparsed content (e.g., non-XML or non-textual) content. Entity content may be either defined entirely within the document (“internal entities”) or external to the document (“external entities”). In parsed entities, the replacement text may include references to other entities via mnemonic strings or standard references (e,g.,
'&'for “&”,'<'for “<”,'©'for “©”) - field [6]— also called data field, represents the basic unit of information storage in a database and is always defined to be an element of a record. A field has associated with it attributes such as name, type (for example, char or int), and length. Other terms used for field include: attribute, entity, or column
- formalism — is one of several alternative computational paradigms for a given theory; a set of symbols and a collection of systematic rules governing their uses and interrelations, as in knowledge representation or logic; from http://www.informatics.susx.ac.uk/books/computers-and-thought/gloss/node1.html
- format [7] — used in the context of XML, it is a representation that conforms to the syntax rules in a given specification
- gateway [8] — is an agent that terminates a message on an inbound interface with the intent of presenting it through an outbound interface as a new message. Unlike a proxy, a gateway receives messages as if it were the final receiver for the message. Due to possible mismatches between the inbound and outbound interfaces, a message may be modified and may have some or all of its meaning lost during the conversion process. For example, an HTTP PUT has no equivalent in SMTP
- identifier [8] — is an unambiguous name for a resource
- individual [9] — is an instance of a class; a single member. Note: within a given class and namespace, individual is synonomous with instance and may only assume a single value for each attribute. However, across namespaces and classes, instances of equivalent classes may represent the identical individual
- information resource [7] — is a resource that has the property that all of its essential characteristics can be conveyed in a message
- information set (or infoset) [9] — is a consistent set of definitions for use in other specifications that need to refer to the information in a well-formed document (XML in the case of this particular specification). A document has an information set if it is well-formed, meaning it contains at least a document information item and several others. Note that, based on this definition, infoset is not a subset of actual data instances
- instance [9] — is a single member or individual within a class. Note: within a given class and namespace, instance is synonomous with individual and may only assume a single value for each attribute. However, across namespaces and classes, instances of equivalent classes may represent the identical individual
- interface [7] — is defined in terms of protocols, by specifying the syntax, semantics, and sequencing constraints of the messages interchanged
- link [7] — is the representation within resource that contains a reference to another resource, expressed with a URI identifying that other resource, this constitutes a link between the two resources. Additional metadata may also form part of the link
- message [7] — may include data as well as metadata about a resource (such as the “Alternates” and “Vary” HTTP headers), the message data, and the message itself (such as the “Transfer-encoding” HTTP header). A message may even include metadata about the message metadata (for message-integrity checks, for instance). According to [8], it is 1. the basic unit of data sent from one Web services agent to another in the context of Web services; or 2. the basic unit of communication between a Web service and a requester
- metadata [9] — is data about data on the Web, including but not limited to authorship, classification, endorsement, policy, distribution terms, IPR, and so on
- model — Note: the W3C provides definitions of subsets of model such as document model, data model, content model, but not for ‘model’ itself
- module [9] — is a collection of semantically related features that represents a unit of functionality
- namespace [7] — is the reference to vocabularies (in which element and attribute names are defined) in a global environment, which reduces the risk of name collisions in a given document when vocabularies are combined. When using namespaces, each local name in a vocabulary is paired with a URI (called the namespace URI) to distinguish the local name from local names in other vocabularies. Designers of data formats and vocabularies who declare namespaces thus make it possible to reuse and combine them in novel ways not yet imagined
- node [9] — is a representation of a resource or a literal in a graph form; specifically, a vertex in a directed labeled graph
- object [9] — is the object of an RDF triple, also an alternative term for individual (used for historical reasons). This is problematic, xxx
- page [9] — in reference to the Web, is a collection of information, consisting of one or more resources, intended to be rendered simultaneously, and identified by a single Uniform Resource Identifier (URI). More specifically, a Web page consists of a resource with zero, one, or more embedded resources intended to be rendered as a single unit, and referred to by the URI of the one resource which is not embedded. (Note: under this definition, a page is a document, but not vice versa.)
- payload [9] — is the information transferred as the payload of an HTTP request or HTTP response
- person or organization [8] — may be the owner of agents that provide or request Web services
- policy [8] — is a constraint on the behavior of agents or person or organization
- property [9] — is a specific attribute with defined meaning that may be used to describe other resources. A property plus the value of that property for a specific resource is a statement about that resource. A property may define its permitted values as well as the types of resources that may be described with this property
- protocol [8] — is a set of formal rules describing how to transmit data, especially across a network. Low level protocols define the electrical and physical standards to be observed, bit- and byte-ordering and the transmission and error detection and correction of the bit stream. High level protocols deal with the data formatting, including the syntax of messages, the terminal to computer dialogue, character sets, sequencing of messages etc. [FOLDOC]
- proxy [8] — is an agent that relays a message between a requester agent and a provider agent, appearing to the Web service to be the requester
- reference architecture [8] — is the generalized architecture of several end systems that share one or more common domains. The reference architecture defines the infrastructure common to the end systems and the interfaces of components that will be included in the end systems. The reference architecture is then instantiated to create a software architecture of a specific system. The definition of the reference architecture facilitates deriving and extending new software architectures for classes of systems. A reference architecture, therefore, plays a dual role with regard to specific target software architectures. First, it generalizes and extracts common functions and configurations. Second, it provides a base for instantiating target systems that use that common base more reliably and cost effectively [Ref Arch]
- registry [8] — is an authoritative, centrally controlled store of information
- representation [7] — is data that encodes information about resource state. Representations do not necessarily describe the resource, or portray a likeness of the resource, or represent the resource in other senses of the word “represent”
- resource [7] — is anything that might be identified by a URI. According to [9], it is further explicated as an abstract object that represents either a physical object such as a person or a book or a conceptual object such as a color or the class of things that have colors. Web pages are usually considered to be physical objects, but the distinction between physical and conceptual or abstract objects is not determinative
- schema [9] — is a document that describes an XML or RDF vocabulary; more generally, any document which describes, in formal way, a language or parameters of a langauge. With specific respect to RDF, it denotes resources which constitute the particular unchanging versions of an RDF vocabulary at any point in time, and is used to provide information (such as organization and relationship) about the interpretation of the statements in an RDF data model. It does not include the values associated with the attributes. According to [10], it is a formal description of the structure of a database: the names of the tables, the names of the columns of each table, and the type and other attributes of each column. (And similarly for the descriptive information of other database-like structures, such as XML files); a conceptual model of the structure of a database that defines the data contents and relationships (a database definition language specification is an implementation of a particular schema)
- secondary resource [7] — is a resource related to another resource through the primary resource with additional identifying information (also known as the fragment identifier)
- semantic [9] — is concerned with the specification of meanings. Often contrasted with syntactic to emphasize the distinction between expressions and what they denote
- serialization [6] — is the process or action of converting something in a serial or into serial form; serialization means to force one-at-a-time access for the purposes of concurrency control, or to encode a data structure as a sequence of bytes [is the one-dimensional form of rendered content]
- service [9] — is an application or abstract resource that provides tasks, computational or informational resources on request.
- set [9] — is a mathematical set. According to [10], it is a well-defined collection of mathematical objects (called elements or members) often having a common property; specifies a one-to-many relationship between record types. One occurrence of the owner record type is related to many occurrences of a member record type. Also called a set type [6]
- statement [9] — is an expression following a specified grammar that names a specific resource, a specific property (attribute), and gives the value of that property for that resource
- structure — several pieces of data treated as a unit
- subtype [5] — is a datatype that is generally related to another datatype (the supertype) by some notion of substitutability, meaning that computer programs written to operate on elements of the supertype can also operate on elements of the subtype
- transformation [9] — is a process that changes a document or object into another, equivalent, object according to a discrete set of rules. This includes conversion tools, software that allows the author to change the schema or model defined for the original document to another one, and the ability to change the markup of lists and convert them into tables or similar
- type [9] — is a property that ties an individual to a class of which it is a member. According to [10], it is a tag attached to variables and values used in determining what values may be assigned to what variables
- URI scheme [7] — is a specification that explains the scheme-specific details of how scheme identifiers are allocated and become associated with a resource. The URI syntax is thus a federated and extensible naming system wherein each scheme’s specification may further restrict the syntax and semantics of identifiers within that scheme
- view [9] — is a particular rendering of the same content, which can be presented in a variety of ways
- vocabulary [9] — is a collection of attributes that adequately describes an associated schema. According to http://www.nmlites.org/standards/language/glossary.html, it is a list or collection of words and definitions, or the language used by a specific group.
In addition to this compilation, another good, comprehensive source for glossary terms is the FEA Data Reference Model (see description above).
Where From Here?
In this first Part I of our Web data model investigations, the limited objective has been to identify and assemble schema, formalisms, structure and syntax across the breadth of the Web.
Such assemblages are often dry and somewhat uninteresting. This one is likely no exception.
On the other hand, the dimensions of Web data interoperability are anything but boring. This is the ground on which the next few generations of Web user (and entrepreneurs) will compete or thrive.
Though in Part II we strive to develop a unified conceptual model, we actually err to embrace ease-of-execution. Such statements, of course, are easier to state than to make happen.
[1] Michael Fourman, “Informatics,” Informatics Research Report EDI-INF-RR-0139, Division of Informatics, University of Edinburgh, July 2002, 9 pp.; see http://www.inf.ed.ac.uk/publications/online/0139.pdf.
[2] Tim Berners-Lee, Wendy Hall, James Hendler, Nigel Shadbolt and Daniel J. Weitzner, “Creating a Science of the Web,” Science 313 (11), August 2006. I personally took up the Web scientist mantle and still proudly wear it as one of its acolytes.
[3] Christian Morbidoni, Giovanni Tummarello, Michele Nucci and Richard Cyganiak, “The DODA Ontology: Lightweight Integration of Semantic Data Access Technologies,” in Proceedings of SWAP 2006, the 3rd Italian Semantic Web Workshop, Pisa, Italy, December 18-20, 2006, CEUR Workshop Proceedings, ISSN 1613-0073. See http://sunsite.informatik.rwth-aachen.de/Publications/CEUR-WS//Vol-201/42.pdf
[4] Jayant Madhavan, Shawn R. Jeffery, Shirley Cohen, Xin (Luna) Dong, David Ko, Cong Yu, and Alon Halevy, “Web-scale Data Integration: You Can Only Afford to Pay As You Go,” Third Biennual Conference on Innovative Data System Research (CIDR 2007), Pacific Grove, CA, January 7 – 10, 2007; see http://www-db.cs.wisc.edu/cidr/cidr2007/papers/cidr07p40.pdf.
[5] For an intial introduction with a focus on Xcerpt, see François Bry, Tim Furche, and Benedikt Linse, “Let’s Mix It: Versatile Access to Web Data in Xcerpt,” in Proceedings of 3rd Workshop on Information Integration on the Web (IIWeb 2006), Edinburgh, Scotland, 22nd May 2006; also as REWERSE-RP-2006-034, see http://rewerse.net/publications/download/REWERSE-RP-2006-034.pdf. For a more detailed treatment, see T. Furche, F. Bry, S. Schaffert, R. Orsini, I. Horrocks, M. Krauss, and O. Bolzer. Survey over Existing Query and Transformation Languages. Deliverable I4-D1a Revision 2.0, REWERSE, 225 pp., April 2006. See http://rewerse.net/deliverables/m24/i4-d9a.pdf.
[6] Lars Marius Garshol, “Living with topic maps and RDF: Topic maps, RDF, DAML, OIL, OWL, TMCL,” in Proceedings of XML Europe 2003. See http://www.ontopia.net/topicmaps/materials/tmrdf.html.
[7] See Web Architecture.
[8] See Web Services.
[9] See W3C Glossary.
[10] See Wiktionary.
[11] See Wikipedia.

Excellent