




Last week I came across a reference from Search Engine Watch — for which I have been a subscriber for many years and have been a speaker at their conferences — that TOTALLY FRIED me. It’s related to a topic near and dear to me, because, I am both the father and the steward. What I am speaking about is the general topic of the “deep Web.” I began a public response to that last week’s posting, but then, after cooling down, simply notified the author, Gary Price, of my attribution concerns. He graciously and subsequently amended his posting with appropriate attribution. Thanks, Gary, for proper and ethical behavior!
With some of the issues handled privately, I decided that discretion was the better part of valor and I would let the topic alone with respect to some of the other parties in the chain of lack of attribution. After all, Gary was merely reporting information from a reporter. The genesis of the issues resided elsewhere.
Then, today, I saw the issue perpetuated still further by the VC backer of Glenbrook Networks, piling onto to the previous egregious oversights. I could sit still no longer.
First, let me say, I am not going to get into the question of “invisible Web” versus “deep Web” (the latter being the term which Thane Paulsen and I coined nearly 5 years ago to reflect dynamic content not accessbile via standard search engine crawlers). Deep Web has become the term of art, much like kleenex, and if you know what the term means then the topic of this post needs no further intro.
However, I’m going to make a few points below about the misappropriation of the term ‘deep Web’ and the technology around it. I believe that some may legitimately say, “Tough luck; it is your responsibility to monitor such things, and if they did not credit or acknowledge your rights, that is your own damn fault.” Actually, I will generally agree with this sentiment.
My real point in this posting, therefore, is not my term versus your term, but the integrity of intellectual property, attribution and “truth” in the dynamic Internet. If I step back from my own circumstance and disappointment, the real implication, I believe, is that future historians will be terribly hard-pressed to discern past truths from Internet content. If we think it is difficult to extract traceable DNA from King Tut today, it will be close to impossible to discern the true genesis, progression, linkages and idea flow based on Internet digital information into the future. But I digress …
Last Week’s Posting
The genesis of this issue began with a posting on Silicon Beat by Matt Marshall, Diving deep into the web: Glenbrook Networks. Marshall is a reporter for the San Jose Mercury News. Much was made of the “deep Web” phenomenon and the fact that Glenbrook Networks now had technology to tap into it. This story was then picked up by the Search Engine Watch blog. SEW is one of the best and most authoritative sources for search engine related information on the Web. The blog author was Gary Price. The SEW blog entry cited two references on deep Web topics, both of which referenced my seminal paper as their own first references. Neither of these press articles mentioned BrightPlanet. I notified Gary Price of what I thought was an oversight of attribution, and he properly and graciously added an addendum to the original piece:
Using this press, Jeff Clavier, one of the VCs backing the vendor, Glenbrook Networks, began flogging the press coverage on his own blog site. There were assertions made in that original piece that deserved countering, but there have been vendors that have come and gone in the past (see below) that have attempted to misappropriate this “space” and its technology and have generally fallen by the wayside or gone out of business. I chose to let the matter go quiet publicly, ground some more enamel off my teeth, and referred the matter to our general counsel for private action.
Today’s Posting
The flogging continued today under a new posting on Jeff Clavier’s site, Glenbrook Networks: Trawling the Deep Web. This new posting extended the misappropriation further, and since part of an ongoing series obviously planned to push the investment, goaded me to finally make a public response. In part, here is some of what that new post said:
Because the Deep Web contains a lot of factual information, it can be seen metaphorically as an ocean with a lot of fish. That is why we call the system that navigates the Deep Web a trawler.
Note that the figures used come directly out of our research, and are frequently used by others without attribution, as is the case here. However, the trawler imagery is especially egregious, since it is a direct rip-off of our original papers!. In fact, here are the two trrawler images from our original Deep Web: Surfacing Hidden Value first published in 2000, the first representing surface content retrieval:

The next image represents deep Web content retrieval:
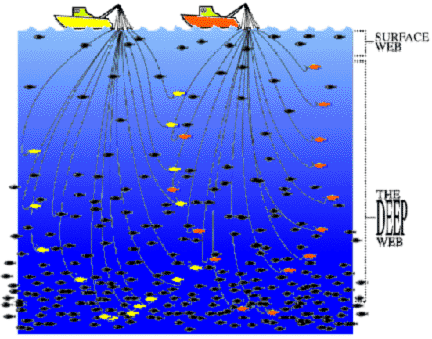
The post then goes on to overview some “technology” with fancy names that is very straightforward, has been documented extensively before by BrightPlanet, and is covered by existing patents to our company.
Misappropriation is Nothing New
Such misappropriations have happened before. In one instance, now out of business, complete portions of BrightPlanet’s white paper were plagiarized on the home page of a competitor. We have also had competitors name themselves after the deep Web (e.g., Deep Web Technologies), appropriate the name and grab Web addresses (Quigo, with http://www.deepweb.com, now largely abandoned), government agencies make videos (the Deep Web DOE deep Web search engine), national clubs form (Deep Web Club), or competitor push products and technologies citing our findings and insights (e.g., Grokker from Groxis or Connotate), all instances without attribution or mention of BrightPlanet.
Imitation is the sincerest form of flattery and enforcement of intellectual property rights depends on the vigilance of the owner. We understand this, though small company size often means it is difficult to discover and police. Indeed, in the initial naming of the “deep Web” we wanted it to become the term of art. By not keeping it proprietary, it largely has. We have thus welcomed the growth of the concept. However, we do not welcome the blatant infringement on intellectual property and technology by competitors. We particularly expect VC-backed companies to adhere to ethical standards. I admonish Glenbrook Networks and its financial backers to provide attribution where attribution is due. This degree of misappropriation is too great. Shame, shame ….
BTW, for the record, you can see the most recent update of my and BrightPlanet’s deep Web paper and analysis at the University of Michigan’s Journal of Electronic Publishing, July 2001. Of course, there remains the definitive information on this topic in spades at BrightPlanet’s Web site.
Defense via Electrons
Actually, the real sadness here is that perhaps what is “truth” is only as good as what has been posted last. Post it last, say it loudest, and the whole world only knows what it sees. The Internet certainly poses challenges to past institutions such as peer review or professional publishing that helped to reinforce standards of truth, verification and defensibility. What standards will emerge on the Web to help affirm authoritativeness?
Certainly, one hopes that the community itself, which has shown constantly it can do so, will find and expose lies, deceit, fraud, or other crimes of the information commons. This appears to work well in the political arena, perhaps is working okay in the academic arena, but how well is it working in the general arena of ideas and intellectual property? Unfortunately, as perhaps this example shows, maybe not so great at times. The thing that I fear is that defense can only occur by how many electrons we shower onto the Internet, how broadly we broadcast them, and how frequently we do so. May the electrons be with you ….
