





Have Linked Data, Microformats Stumbled into an Adaptive Design?; Benefits from Keeping the TBox and ABox Separate
I was glad to see Kendall Clark pick up on parts of my earlier piece on Thinking ‘Inside the Box’ with Description Logics. He took one point of view in his posting — that I mostly agree with — but I’d also like to reinforce some other thoughts. And, those thoughts are: description logics (DL) provides earlier lessons and insights that our current zeal for linked data should not overlook, and the lessons we can gain from DL are really fundamental and architectural.
For those of you who have not read Kendall’s piece — which I heartily recommend — let me give you my Cliffs Note’s summary: there are those within the semantic Web community that want to capture the conceptual relationships within knowledge and domains, the Maximum Fidelity tribe, and then those that want to link and describe as many things as possible, the Maximum Scalability tribe, with those (like Kendall’s firm, Clark & Parsia) residing in the middle and following the precepts of DL. The theme is that extremes exist and need to be bridged. [1]
Posing these contrasts is an effective way to describe different ideas and approaches, but, like all straw men, perhaps it hides nuances and complexity. And, as I note below, it may also pose the wrong straw man dichotomy.
We Are All Tribes of One
Jim Hendler, for one, took exception to Kendall’s characterization to make the obvious point that different use cases demand different approaches. What was interesting, however, in these interchanges was that a nerve was seemingly struck about differences in viewpoints and approaches. Indeed, the very reference to “tribes” seemed to bring out the (ahem) tribal response.
So, just so we are clear, in what I say below I take on the position of a tribe of one; that is, my own opinion. Of course, this is what all of us do. By positing tribes and viewpoints we simplify what is nuanced and subtly convey that opinions are cultural (“tribal”) and not subject to learning and change. Perhaps within the temporal viewpoint of whatever may be today’s trends and “memes” such thinking may hold, but I fundamentally disagree with such a static view of collective understanding and communities over more meaningful periods of years or decades. But, I digress. . . .
At the risk of being simplistic, I think we can say that there was a rich academic and intellectual history behind description logics going back to the early 1990s [2]. Then, with the seminal semantic Web paper built from thinking in the late 90s by Berners-Lee and published by him and Hendler and Lassila in 2001 in Scientific American [3], a real marker was put down for machine-readable and -actionable data (via “agents”) accessible on the Web. Many have been disappointed at the slow pace of the semWeb’s unfolding and some have blamed and rejected AI and “big” ontologies for this slowness. As usable standards finally emerged, a newer set of acolytes pushed “just getting data out there” and RDF linked data began to assume prominence from about 2006 onward, spearheaded by DBpedia and the linked open data community.
In so many ways we are coming full circle — coming back to the future — in seeing how our new linked data techniques can again benefit from this earlier DL thinking. Rather then poles and spectrums, I think we are experiencing the need to revisit our intellectual past now that workable publishing mechanisms and scalability and organization assume real prominence. Though clearly not intentional, the linked data community (and, in a related way, microformats), may just have stumbled upon a very cool architectural design that can leverage DL precepts.
Some Terminology Revisited
Some of this DL and semWeb terminology can be off-putting. But it is helpful to know the lingo if one wants to look into the technical literature. Though most of this stuff can be described without resorting to such terms and can be readily grasped on an intuitive basis, here are some important grounding terms:
- TBox — according to [2], a TBox “contains intensional knowledge in the form of a terminology (hence the term ‘TBox,’ but ‘taxonomy’ could be used as well) and is built through declarations that describe general properties of concepts. Because of the nature of the subsumption relationships among the concepts that constitute the terminology, TBoxes are usually thought of as having a lattice-like structure; this mathematical structure is entailed by the subsumption relationship — it has nothing to do with any implementation.” A TBox uses a controlled vocabulary to define the concepts and roles of a domain of interest and the relations or properties amongst them
- ABox — according to [2], an ABox “contains extensional knowledge — also called assertional knowledge (hence the term ‘ABox’) — that is specific to the individuals of the domain of discourse.” An ABox provides the concept and role membership assertions for instance data, as well as assertions or “facts” about the attributes of those instances using the same controlled vocabulary as defined in the TBox
- First-order logic (FOL) — is a formal deductive system with unambiguous logic and mathematical structures for declaring, testing and inferring propositions (statements) and predicates (relations). A first-order theory consists of a set of axioms (usually finite or recursive) and the statements deducible from them based on FOL’s base logical axioms (such as the operators found in classical set theory, which itself is built on FOL)
- Description logics (DL) — are any of a family of knowledge representation languages that can be translated and characterized according to first-order logic. A DL language has a syntax that consists of unary predicate symbols to denote concepts, binary relations to denote roles, and recursion. DL semantics define concepts as sets of individuals and roles as sets of pairs of individuals. The expressivity of a DL language is a function of the logical operators the language supports (shown with representations such as
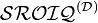 , the expressiveness of OWL 2). DL languages can be translated into other DL languages that support the same expressivity, regardless of syntax, but more expressive languages can not be equivalently represented by less expressive ones. The current OWL dialects of OWL Lite and OWL DL are DL languages
, the expressiveness of OWL 2). DL languages can be translated into other DL languages that support the same expressivity, regardless of syntax, but more expressive languages can not be equivalently represented by less expressive ones. The current OWL dialects of OWL Lite and OWL DL are DL languages - Axiom — in traditional logic or FOL, an axiom (also called a ‘postulate’) is a proposition that is not proved or demonstrated but considered to be either self-evident or consistent with the base logic of the system. As such, its truth is taken for granted and the axiom serves as a starting point for deducing and inferring other (theory-dependent) truths
- Intensional — is a form of set membership that is based on the propositions and concepts which defines the set; there may be many possible members that remain unenumerated so long as they meet the conditions for membership. The intensional principal judges objects to be a member based on the properties or conditions they must have
- Extensional — is a form of set membership that arises from (“extends”) its listed set members. The extensional principle judges objects to be a member if they have the same external characteristics (whether as explicitly defined properties or not)
- Ontology — as used in knowledge representation or information science, this term is most often defined using Tom Gruber’s “explicit specification of a conceptualization” [4]. In practice on the semantic Web, it is any defined schema or data record structure including the most lightweight controlled vocabularies and structures (such as microformats). In DL, both ABox and TBox specifications and statements are lumped under the term
- Vocabulary — also ‘controlled vocabulary,’ is an organized, variously structured set of terms used for information retrieval or characterization. In its simplest form, a controlled vocabulary is merely a list for checking possible matches for set membership or not; at its more complex, it is the set of terms contained within a detailed and specified ontology or schema with formalized (axiomatized) relationships
- Knowledge base — in the DL community, a knowledge base is simply defined as TBox + Abox. In other words, a knowledge base is a logical schema of roles and concepts and the relationships between them (the TBox) as populated by the actual data (instances) asserting memberships and attributes (“facts”) (the ABox).
TBox v ABox: Different Purposes and Roles
Within description logics and for our purposes herein, the two concepts we will most focus upon are the ABox and the TBox. As the definitions above suggest, the TBox is more structural and reflects the logical and conceptual relationships within a domain; that is, the role and concept and class relationships. The ABox provides the data (instance) records and characterizations within that schema; that is the instances and facts assertions. By analogy, in a conventional relational database system, the database or logical schema would correspond to the TBox; the actual data records or tables would correspond to the ABox.
These distinctions suggest very different purposes and roles, then, for the TBox and the ABox:
| TBox | ABox |
|
|
While certainly many of the ABox tests and checks require TBox structure, there is a pretty clear separation of purpose and role. Moreover: 1) the scale of the information in each “box” is vastly different (perhaps a few to hundreds to at most thousands of concepts in the TBox in contrast to potentially millions or more instances in ABoxes); and 2) ABox dataset repositories may also be (indeed, often are!) numerous, spatially distributed and semantically heterogeneous.
The Wisdom of Separating Concerns
DL and semantic Web stuff in general are data and logic models, not architectural guidance. So, rarely does one see discussion of the architectural imperatives that some of these logical underpinnings provide. We see knowledge bases and ontologies both used as umbrella terms encompassing both the ABox and the TBox.
However, our own deployment experiences and the literature suggest there are manifest advantages to keeping the TBox and ABox separate:
| Advantages of Keeping the TBox and ABox Separate |
|
It would be useful to refrain from lumping the very different purposes of ABoxes and TBoxes under the umbrella rubric of ‘ontology’. It would also be useful for designers and vocabulary authors to be more explicit in their own minds as to purpose and content when formulating new ontologies. Smushing all of these concepts into one bubbling mess may not lead to clarity nor good performance.
A Simple Schematic of Best Practice
Taking these basic ideas we can visualize a general schematic for best practice splits within the ontology or knowledge base:
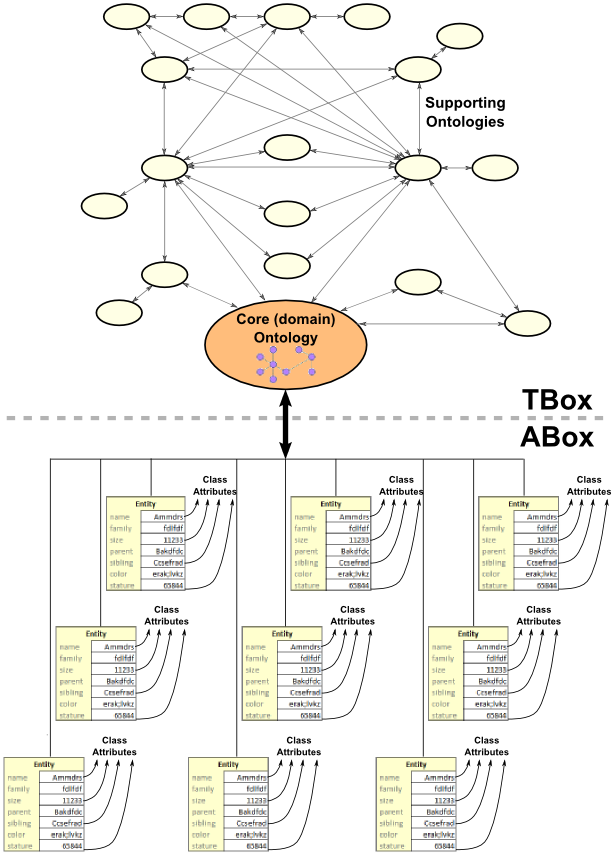
The TBox is clearly focused on the domain at hand, but also includes links and equivalents to external ontologies. The TBox level should be entirely free of instance data, though all attributes, properties and concepts that might be found at the ABox level are also defined with their relationships at the TBox level. Like any semWeb ontology, this TBox level should also re-use common Web ontologies such as FOAF, SIOC, UMBEL, etc.
It is also the case that because of the reasoning needs at the TBox layer, the semantic Web language used should likely be a dialect of OWL (see below).
(BTW, for my own practice, I will try to limit my use of the ‘ontology’ term to the concepts and classes at this TBox level.)
The ABox level, in contrast, may consist of multiple datasets and name spaces. These structures are most appropriately seen as lightweight controlled vocabularies with limited structure; if written by scratch perhaps limited to RDF or RDFS (the schema variant). This layer, however, can also remain in non-semWeb native form — such as RDBMS data tables, microformats or other formats — that are wrapperized for interoperability through one or more ‘RDFizers‘ or GRDDL.
These structures should likely not make many external assertions, if any, and if done, perhaps in separate mapping or linkage file that can be processed and analyzed independently. It is important, however, to make sure that all attributes at this ABox layer have a counterpart with relationships and structure defined at the TBox layer.
This architectural design enables complete independence of the instance datasets from the inferencing logic or federation that might be applied to them.
The Relevance to Linked Data Instances
Since it first took off in 2006, linked data and the various datasets now shown in the ‘LOD cloud‘ have been dominated by instance data. There are perhaps 10 million to 20 million instance objects available as linked data, many of which are derived from Wikipedia (via DBpedia) with attributes or structure coming from the Wikipedia infoboxes.
“There need not be a trade-off between expressiveness and scalability. Proper design, language choice and architecture can readily achieve both — while maintaining independence of scope or purpose.”
A similarly fast explosion has taken place with structured records via microformats and other simple data structures. For example, some earlier estimates suggest there are perhaps more than 2 billion pages that include microformats [10].
I have at times recently made comments about the dominance of instance data within the linked data community and the need for organizing structure. While this observation, I believe, remains true and provides a rationale for UMBEL as an organizing subject structure (or any other organizing structure, for that matter), perhaps I have been missing a more fundamental point: linked data (at least as practiced to date) is really about exposing ABoxes with simple structure. Perhaps, by serendipity, linked data (and other light structures like microformats) are showing the way to a distributed, mixed ABox-TBox structure for the Web.
With this altered viewpoint, a number of new observations emerge:
- Linked data instance structures perhaps need to be consciously designed as such, with lightweight structure and limited external (OWL-based or TBox-oriented) class structure
- The recent interest shown in so-called VoCamps (for lightweight vocabulary development) and voiD (vocabulary of interlinked datasets) might be usefully viewed specifically through an ABox “lens” with perhaps best practices for structures and vocabulary syntaxes to emerge
- TBox class and relationship structures should remain apart from the instance data and can be used to operate independently of the datasets
- Architectural and design changes might also emerge through clear separation of ABox and TBox that can benefit semantic Web scalability.
Linked data and microformats and other lightweight structures are now giving us the exposed instance data to begin reasoning and showing differences due to inferencing and other logic advantages for the semantic Web. Now that the ABox is being proven, let’s move on and stress-test the TBox!
OWL 2 and Query Rewriting
Since the first version of OWL there has been confusion and some limitations with the dialects of the language. Only OWL Full allowed classes to be treated both as instances and classes (so-called metamodeling), and was therefore used as the basis for mapping UMBEL, for example, to RDF and RDFS vocabularies and to Cyc. This design was necessary, but left UMBEL undecidable using standard DL reasoners; only the two dialects of OWL DL and OWL Lite met description logics requirements.
Indeed, it was even hard to determine what dialect an OWL file represented, among many other problems and issues. The technical committee behind OWL 2, in fact, has written an excellent critique of issues with this first version of OWL [11].
For nearly two years the next version of OWL, OWL 2, has been undergoing development, with the last draft now published and available for last comment before January 23 [12]. Lessons and refinements to the use of DL have also occurred. Some have criticized this effort and have criticized the need for OWL 2’s growing expressiveness and vocabulary [see 1, for example]. I believe these criticisms to be unfair and to miss many of the thoughtful improvements in this new version.
Version control and expressiveness are two of these benefits. A broader benefit, though, has been the keen attention the developers have given to compliance with description logics and the ability to formulate fragments (called “profiles”) that only present subsets of DL useful for computational considerations [13]. For example, one profile, OWL 2 QL, appears well suited to the ABox; another, EL, appears well suited to the TBox. Users and tools builders may define other subsets of OWL 2 to deal with different use cases.
What is emerging are possible design patterns that would have comprehensive TBox guidance and inference structures that first receive a query, then do query rewriting for less capable OWL dialects and mapping to distributed ABox datasets, some of which might be kept in native relational DB or other structural forms [9, 14, 15]. Other approaches and designs, such as overviewed for DLDB2, KAON2, OWLIM, BigOWLIM and Minerva, are testing other architectural and DL combinations [see 15]. And, at the level of the specific triplestore, other optimizations are being made such as owl:sameAs or query rewrite with Virtuoso [16]. This new version of OWL and its profiles have adapted to past lessons and can be matched well to the emerging hardware and architectural designs.
These changes appear to now provide the option for various dialects of OWL to be matched with reasoners and architectural designs in order to optimize for different purposes. Rather than a spectrum, we appear to be learning and maturing. Hopefully, getting back to the architectural implications of the TBox – ABox split can show us there need not be a trade-off between expressiveness and scalability. Proper design, language and dialect choice, and architecture can readily achieve both — while maintaining independence of scope or purpose.
Thanks, OWL 2! You have fulfilled your commitment to description logics. It is now our turn to figure out the best practices for working with these tools.
