




 Technical Debts Accrue from Dependencies, Adapting to Change, and Maintenance
Technical Debts Accrue from Dependencies, Adapting to Change, and Maintenance
Machine learning has entered a golden age of open source toolkits and much electronic and labeled data upon which to train them. The proliferation of applications and relative ease of standing up a working instance — what one might call “first twitch” — have made machine learning a strong seductress.
But embedding machine learning into production environments that can be sustained as needs and knowledge change is another matter. The first part of the process means that data must be found (and labeled if using supervised learning) and then tested against one or more machine learners. Knowing how to use and select features plus systematic ways to leverage knowledge bases are essential at this stage. Reference (or “gold”) standards are also essential as parameters and feature sets are tuned for the applicable learners. Only then can one produce enterprise-ready results.
Those set-up efforts are the visible part of the iceberg. What lies underneath the surface, as a group of experienced Google researchers warns us in a recent paper, Hidden Technical Debt in Machine Learning Systems [1], dwarfs the initial development of production-grade results. Maintaining these systems over time is “difficult and expensive”, exposing ongoing requirements as technical debt. Like any kind of debt, these requirements must be serviced, with delays or lack of a systematic way to deal with the debt adding to the accrued cost.
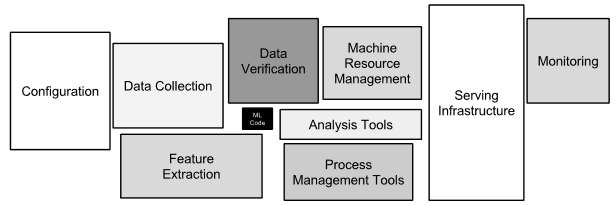
The authors argue that ML installations incur larger than normal technical debt, since machine learning has to be deployed and maintained similar to traditional code, plus the nature of ML imposes additional and unique costs. Some of these sources of hidden cost include:
- Complex models with indeterminate boundaries — ML learners are entangled with multiple feature sets; changing anything changes everything (CACE) say the authors
- Costly data dependencies — learning is attuned to the input data; as that data changes, learners may need to be re-trained with generation anew of input feature sets; existing features may cease to be significant
- Feedback loops and interactions — the best performing systems may depend on multiple learners or less than obvious feedback loops, again leading to CACE
- Sub-optimal systems — piecing together multiple open source pieces with “glue code” or using multi-purpose toolkits can lead to code and architectures that are not performant
- Configuration debt — set-up and workflows need to work as a system and consistently, but tuning and optimization are generally elusive to understand and measure
- Infrastructure debt — efforts in creating standards, testing options, logging and monitoring, managing multiple models, etc., are likely all more demanding than traditional systems, and
- A constantly changing world — the nature of knowledge is it is always under constant flux. We learn more, facts and data change, new perspectives need to be incorporated, all of which need to percolate through the learning process and then be supported by the infrastructure.
The authors of the paper do not really offer any solutions or guidelines to these challenges. However, highlighting the nature of these challenges — as this paper does well — should forewarn any enterprise considering its own machine learning initiative. These costs can only be managed by anticipating and planning for them, preferably supported by systematic and repeatable utilities and workflows.
I recommend a close read of this paper before budgeting your own efforts.
(Hat tip to Mohan Bavirisetty for posting the paper link on LinkedIn.)
