




There was an interesting exchange between Martin Nisenholtz and Tim O’Reilly at a recent Union Square Session on the topic of peer production and open data architectures. Martin was questioning how prominent “winners” like Wikipedia may prejudice our view of the likelihood of Web winners in general. Here’s the exchange:
NISENHOLTZ: I sort of call it the lottery syndrome. There was a Powerball lottery yesterday. Tons of people entered it. We know that someone won in Oregon . . . we also know that the chances of winning were one in 164 million . . . .I guess what I’m struggling with is how we measure the number of peer production efforts that get started versus Wikipedia, which has become the poster child, the lottery, the one in 164 million actually works. Now it may not be one in 164 million. It may be one in 10. It may be one in 50, but I think that groups of people like [prominent Web thinkers] tend to create the lottery winner and hold the lottery winner up as the norm.
O’REILLY: Look at Source Forge, there’s something like 104,000 projects on Source Forge. You can actually do a long tail distribution and figure out how many of them — but … I would guess that one in like … 154 million are probably out of those 100,000 projects, there are probably, you know, at least 5,000 who have made significant reputation gains as a result of their work. Maybe more. But, again, somebody should go out and measure that.
It just so happens that I had recently done that SourceForge project analysis in June, which is mostly still relevant since only a few months old. That info is reproduced below.
Strong Growth for Open Source Projects
In open source there are some big visibility winners and lots of activity. (For an excellent overview of the leading and successful open source projects, see Uhlman.[1]) The numbers of these projects have grown rapidly, increasing by about 30% to 100,000 projects in the past year alone. However, like virtually everything else, the relative importance or use of open source projects tend to follow standard power curve distributions.
The truly influential projects only number in the hundreds, as figures from SourceForge, a clearinghouse solely devoted to open source projects, indicate. There is a high degree of fluctuation, but as of May 2005 there were on the order of perhaps 13 million total software code downloads per week from SourceForge (A). Though SourceForge statistics indicate it has some 100,000 open source projects within its database, in fact fewer than half of those have any software downloads, only 1.7% of the listed projects are deemed mature, and only about 15,000 projects are classified as production or stable.[2]
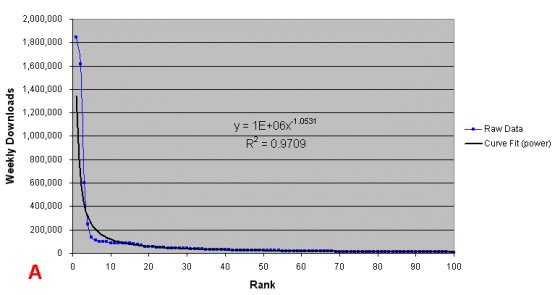
But power curve distributions indicate even a much smaller number of projects account for most activity. For example, the top 100 SourceForge projects account for 60% of total downloads, with the top two, Azureus and eMule, alone accounting for about one-quarter of all downloads. Indeed to even achieve 1000 downloads per day, a SourceForge open source project must be within the top 150 projects, or just 0.2% of those active or 0.1% of total projects listed.[3]
Similar trends are shown for cumulative downloads. Since its formation in 2000, software code downloads from SourceForge have totalled nearly one billion (actually, an estimated 892 million as of May 2005) (B, logarithmic scale). Again, however, a relatively small number of projects has dominated.
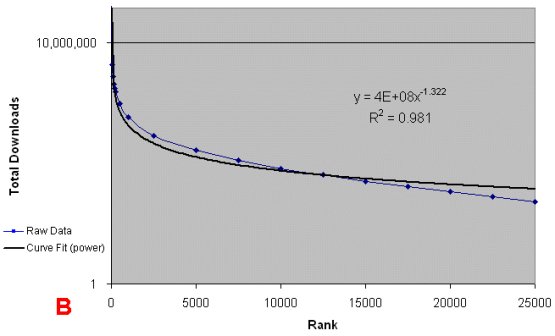
For example, 60% of all downloads throughout the history of SourceForge have occurred for the 100 most active projects. It can be reasonably defended that the number of open source projects with sufficient reach and use to warrant commercial attention probably total fewer than 1,000.
Open Source is Not the Same as Linux
Some observers, such as for example the Open reSource site[4], tends to equate open source with the Linux operating system and all aspects around it. While it is true that Linux was one of the first groundbreakers in open source and is the operating system with the largest open source market share, that is still only about one-half of all projects according to SourceForge statistics:
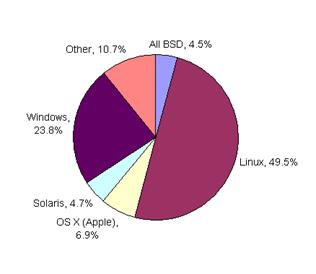
Windows projects have been growing in importance, along with Apple. In terms of programming languages, various flavors of C, followed by the ‘P’ languages (PHP, Python, Perl) and Java are the most popular. Note, however, that many projects combine languages, such as C for core engines and PHP for interfaces. Also note that many projects have multiple implementations, such as support for both Linux and Windows installations and perhaps PHP and Perl versions. Finally, the popularity of the Linux – Apache – MySQL and P languages have earned many open source projects the LAMP moniker. When replaced by Windows this is sometimes known as WAMP or with Java its known as LAMJ:
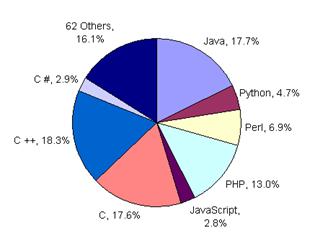
Because of the diversity of users, larger and more successful projects tend to have multiple versions.
Few Active Developers Support Most Projects
Despite source code being open and developers invited for participation, most mature open source projects in fact receive little actual development attention and effort from outsiders. Entities that touch and get involved in an open source project tend to form a pyramid of types. This pyramid, and the types of entities that become involved from the foundation upward, can be characterized as:
- Users — by far the largest category, users simply want use of no cost software or some comfort the code base is available (as below)
- Serious downloaders — there is an active class of Internet users that spend considerable time downloading application, game or other software, installing it, and then removing it and moving on. The motivations for this large software grazing class varies. Some are interested in seeing new software ideas, installation methods, user interfaces and the like; some are consultants or pundits that want to be current with new systems and trends; others simply are the Internet equivalent of serial mall shoppers. Whatever the motivation, this class of users acts to inflate download statistics, and sometimes may be key influence makers or spreaders of word-of-mouth, but are unlikely to establish a lasting relationship with a project
- Linkers and embedders — these users are at the serious end of the actual user group and have clear ideas about needed functionality and will expend considerable effort to link or embed a promising new open source project into their current working environment. This level of engagement requires a considerable amount of effort and acts to increase the switching costs of later moving away from the project
- Extenders — these individuals create the wrappers and other APIs for establishing interoperabiltiy and use between existing components in currently disparate environments (Apache, IIS or Tomcat; Windows, Linux; PHP, PERL or Java, etc.) or critically bring the project to other languages, human or programmatic. They are perhaps the most attractive group of users from a project influence standpoint. This category is the major source of external innovation
- Active developers — this is the standard assumed class of developers who actually sign-up and do major work on the initial project. But a surprising few number of developers participate in this category, and this category, like the next one, is close to non-existant for open source projects that follow the license choice model as proposed for BrightPlanet below
- Code forkers — some mature and larger visibility open source projects (not including the license choice model) may witness a major breakaway in development. This can occur because of some differences in philosopy (some of the Linux variants), loss of interest by the original sponsor (HTMLarea WYSIWG editor, for example), or branching to different programming languages (many of the CMS variants). Code forking can be a source of innovation and use expansion, but also can serve to kill the original branch and leave existing users at a dead end.
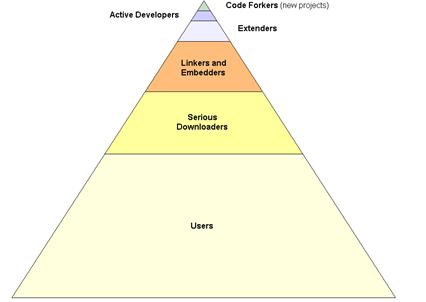
Most effort around successful open source projects is geared to extending the environments or interoperability of those projects with others — both laudable objectives — rather than fundamental base code progression.
Mature Projects are Stable, Scalable, Reliable and Functional
David Wheeler has maintained the major summary site for open source performance statistics and studies for many years.[5] In compiling literally hundreds of independent studies, Wheeler observes that “OSS/FS [open source software/free software] . . . is often the most reliable software, and in many cases has the best performance. OSS/FS scales, both in problem size and project size. OSS/FS software often has far better security, perhaps due to the possibility of worldwide review. Total cost of ownership for OSS/FS is often far less than proprietary software, especially as the number of platforms increases.” However, while obviously an advocate, Wheeler is also careful to not claim these advantages across the board or for all open source projects.
Indeed, most of the studies cited by Wheeler obviously deal with that small subset of mature open source projects, and often surrounding Linux and not necessarily some of the new open source projects moving towards applications.
Probably the key point is that even though there may be ideological differences between advocates for or against open source, there is nothing inherent in open-source software that would make it inferior or superior to proprietary software. Like all other measures, the quality of the team behind an initiative is the driving force for quality as opposed to open or closed code.
[1] D. Uhlman, Open Source Business Applications, see http://www.socallinuxexpo.org/presentations/david_uhlman_scale3x.pdf
[2] I’d like to thank Matt Asay for pointing the way to digging into SourceForge statistics. It is further worth recommending his “Open Source and the Commodity Urge: Distruptive Models for a Distruptive Development Process,” November 8, 2004, 17 pp., which may be found at: http://www.open-bar.org/docs/matt_asay_open_source_chapter_11-2004.pdf
[3] Of course, downloads may occur at other sites than SourceForge and there are other proxies for project importance or activity, such as pageviews, the measure that SourceForge itself uses. However, as the largest compilation point on the Web for open source projects, the SourceForge data are nonethless indicative of these power curve distributions.
[4] See Open reSource http://sterneco.editme.com/
[5] D.A. Wheeler, Why Open Source Software / Free Software (OSS/FS, FLOSS, or FOSS)? Look at the Numbers!, versuion updated May 5, 2005. See http://www.dwheeler.com/oss_fs_why.html. The paper also has useful summaries of market informatin and other open source statistics.
