




 Adaptive Information is a Hammer, but Genes are Not a Nail
Adaptive Information is a Hammer, but Genes are Not a Nail
Since Richard Dawkins first put forward the idea of the “meme” in his book The Selfish Gene some 35 years ago [1], the premise has struck in my craw. I, like Dawkins, was trained as an evolutionary biologist. I understand the idea of the gene and its essential role as a vehicle for organic evolution. And, all of us clearly understand that “ideas” themselves have a certain competitive and adaptive nature. Some go viral; some run like wildfire and take prominence; and some go nowhere or fall on deaf ears. Culture and human communications and ideas play complementary — perhaps even dominant — roles in comparison to the biological information contained within DNA (genes).
I think there are two bases for why the “meme” idea sticks in my craw. The first harkens back to Dawkins. In formulating the concept of the “meme”, Dawkins falls into the trap of many professionals, what the French call déformation professionnelle. This is the idea of professionals framing problems from the confines of their own points of view. This is also known as the Law of the Instrument, or (Abraham) Maslow‘s hammer, or what all of us know colloquially as “if all you have is a hammer, everything looks like a nail“ [2]. Human or cultural information is not genetics.
The second — and more fundamental — basis for why this idea sticks in my craw is its mis-characterization of what is adaptive information, the title and theme of this blog. Sure, adaptive information can be found in the types of information structures at the basis of organic life and organic evolution. But, adaptive information is much, much more. Adaptive information is any structure that provides arrangements of energy and matter that maximizes entropy production. In inanimate terms, such structures include chemical chirality and proteins. It includes the bases for organic life, inheritance and organic evolution. For some life forms, it might include communications such as pheromones or bird or whale songs or the primitive use of tools or communicated behaviors such as nest building. For humans with their unique abilities to manipulate and communicate symbols, adaptive information embraces such structures as languages, books and technology artifacts. These structures don’t look or act like genes and are not replicators in any fashion of the term. To hammer them as “memes” significantly distorts their fundamental nature as information structures and glosses over what factors might — or might not — make them adaptive.
I have been thinking of these concepts much over the past few decades. Recently, though, there has been a spate of the “meme” term, particularly on the semantic Web mailing lists to which I subscribe. This spewing has caused me to outline some basic ideas about what I find so problematic in the use of the “meme” concept.
A Brief Disquisition on Memes
As defined by Dawkins and expanded upon by others, a “meme” is an idea, behavior or style that spreads from person to person within a culture. It is proposed as being able to be transmitted through writing, speech, gestures or rituals. Dawkins specifically called melodies, catch-phrases, fashion and the technology of building arches as examples of memes. A meme is postulated as a cultural analogue to genes in that they are assumed to be able to self-replicate, mutate or respond to selective pressures. Thus, as proposed, memes may evolve by natural selection in a manner analogous to that of biological evolution.
However, unlike a gene, a structure corresponding to a “meme” has never been discovered or observed. There is no evidence for it as a unit of replication, or indeed as any kind of coherent unit at all. In its sloppy use, it is hard to see how “meme” differs in its scope from concepts, ideas or any form of cultural information or transmission, yet it is imbued with properties analogous to animate evolution for which there is not a shred of empirical evidence.
One might say, so what, the idea of a “meme” is merely a metaphor, what is the harm? Well, the harm comes about when it is taken seriously as a means of explaining human behavior and cultural changes, a field of study called memetics. It becomes a pseudo-scientific term that sets a boundary condition for understanding the nature of information and what makes it adaptive or not [3]. Mechanisms and structures appropriate to animate life are not universal information structures, they are simply the structures that have evolved in the organic realm. In the human realm of signs and symbols and digital information and media, information is the universal, not the genetic structure of organic evolution.
The noted evolutionary geneticist, R.C. Lewontin, one of my key influences as a student, has also been harshly critical of the idea of memetics [4]:
Consistent with my recent writings about Charles S. Peirce [5], many logicians and semiotic theorists are also critical of the idea of “memes”, but on different grounds. The criticism here is that “memes” distort Peirce’s ideas about signs and the reification of signs and symbols via a triadic nature. Notable in this camp is Terrence Deacon [6].
Information is a First Principle
It is not surprising that the concept of “memes” arose in the first place. It is understandable to seek universal principles consistent with natural laws and observations. The mechanism of natural evolution works on the information embodied in DNA, so why not look to genes as some form of universal model?
The problem here, I think, was to confuse mechanisms with first principles. Genes are a mechanism — a “structure” if you will — that along with other forms of natural selection such as the entire organism and even kin selection [7], have evolved as means of adaptation in the animate world. But the fundamental thing to be looked for here is the idea of information, not the mechanism of genes and how they replicate. The idea of information holds the key for drilling down to universal principles that may find commonality between information for humans in a cultural sense and information conveyed through natural evolution for life forms. It is the search for this commonality that has driven my professional interests for decades, spanning from population genetics and evolution to computers, information theory and semantics [8].
But before we can tackle these connections head on, it is important to address a couple of important misconceptions (as I see them).
Seque #1: Information is (Not!) Entropy
In looking to information as a first principle, Claude Shannon‘s seminal work in 1948 on information theory must be taken as the essential point of departure [9]. The motivation of Shannon’s paper and work by others preceding him was to understand information losses in communication systems or networks. Much of the impetus for this came about because of issues in wartime communications and early ciphers and cryptography. (As a result, the Shannon paper is also intimately related to data patterns and data compression, not further discussed here.)
In a strict sense, Shannon’s paper was really talking about the amount of information that could be theoretically and predictably communicated between a sender and a receiver. No context or semantics were implied in this communication, only the amount of information (for which Shannon introduced the term “bits” [10]) and what might be subject to losses (or uncertainty in the accurate communication of the message). In this regard, what Shannon called “information” is what we would best term “data” in today’s parlance.
The form that the uncertainty (unpredictability) calculation that Shannon derived:
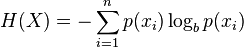
very much resembled the mathematical form for Boltzmann‘s original definition of entropy (as elaborated upon by Gibbs, denoted as S, for Gibb’s entropy):
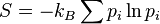
and thus Shannon also labelled his measure of unpredictability, H, as entropy [10].
After Shannon, and nearly a century after Boltzmann, work by individuals such as Jaynes in the field of statistical mechanics came to show that thermodynamic entropy can indeed be seen as an application of Shannon’s information theory, so there are close parallels [11]. This parallel of mathematical form and terminology has led many to assert that information is entropy.
I believe this assertion is a misconception on two grounds.
First, as noted, what is actually being measured here is data (or bits), not information embodying any semantic meaning or context. Thus, the formula and terminology is not accurate for discussing “information” in a conventional sense.
Second, the Shannon methods are based on the communication (transmittal) between a sender and a receiver. Thus the Shannon entropy measure is actually a measure of the uncertainty for either one of these states. The actual information that gets transmitted and predictably received was formulated by Shannon as R (which he called rate), and he expressed basically as:
R = Hbefore – Hafter
R, then, becomes a proxy for the amount of information accurately communicated. R can never be zero (because all communication systems have losses). Hbefore and Hafter are both state functions for the message, so this also makes R a function of state. So while there is Shannon entropy (unpredictability) for any given sending or receiving state, the actual amount of information (that is, data) that is transmitted is a change in state as measured by a change in uncertainty between sender (Hbefore) and receiver (Hafter). In the words of Thomas Schneider, who provides a very clear discussion of this distinction [12]:
Information is always a measure of the decrease of uncertainty at a receiver.
These points do not directly bear on the basis of information as discussed below, but help remove misunderstandings that might undercut those points. Further, these clarifications make consistent theoretical foundations of information (data) with natural evolution while being logically consistent with the 2nd law of thermodynamics (see next).
Seque #2: Entropy is (Not!) Disorder
The 2nd law of thermodynamics expresses the tendency that, over time, differences in temperature, pressure, or chemical potential equilibrate in an isolated physical system. Entropy is a measure of this equilibration: for a given physical system, the highest entropy state is one at equilibrium. Fluxes or gradients arise when there are differences in state potentials in these systems. (In physical systems, these are known as sources and sinks; in information theory, they are sender and receiver.) Fluxes go from low to high entropy, and are non-reversible — the “arrow of time” — without the addition of external energy. Heat, for example, is a by product of fluxes in thermal energy. Because these fluxes are directional in isolation, a perpetual motion machine is shown as impossible.
In a closed system (namely, the entire cosmos), one can see this gradient as spanning from order to disorder, with the equilibrium state being the random distribution of all things. This perspective, and much schooling regarding these concepts, tends to present the idea of entropy as a “disordered” state. Life is seen as the “ordered” state in this mindset. Hewing to this perspective, some prominent philosophers, scientists and others have sometimes tried to present the “force” representing life and “order” as an opposite one to entropy. One common term for this opposite “force” is “negentropy” [13].
But, in the real conditions common to our lives, our environment is distinctly open, not closed. We experience massive influxes of energy via sunlight, and have learned as well how to harness stored energy from eons past in further sources of fossil and nuclear energy. Our open world is indeed a high energy one, and one that increases that high-energy state as our knowledge leads us to exploit still further resources of higher and higher quality. As Buckminster Fuller once famously noted, electricity consumption (one of the highest quality energy resources found to date) has become a telling metric about the well-being and wealth of human societies [14].
The high-energy environments fostering life on earth and more recently human evolution establish a local (in a cosmic sense) gradient that promotes fluxes to more ordered states, not lesser unordered ones. These fluxes remain faithful to basic physical laws and are non-deterministic [15]. Indeed, such local gradients can themselves be seen as consistent with the conditions initially leading to life, favoring the random event in the early primordial soup that led to chemical structures such as chirality, auto-catalytic reactions, enzymes, and then proteins, which became the eventual building blocks for animate life [16].
These events did not have preordained outcomes (that is, they were non-deterministic), but were the result of time and variation in the face of external energy inputs to favor the marginal combinatorial improvement. The favoring of the new marginal improvement also arises consistent with entropy principles, by giving a competitive edge to those structures that produce faster movements across the existing energy gradient. According to Annila and Annila [16]:
Via this analysis we see that life is not at odds with entropy, but is consistent with it. Further, we see that incremental improvements in structure that are consistent with the maximum entropy production principle will be favored [17]. Of course, absent the external inputs of energy, these gradients would reverse. Under those conditions, the 2nd law would promote a breakdown to a less ordered system, what most of us have been taught in schools.
With these understandings we can now see the dichotomy as life representing order with entropy disorder as being false. Further, we can see a guiding set of principles that is consistent across the broad span of evolution from primordial chemicals and enzymes to basic life and on to human knowledge and artifacts. This insight provides the fundamental “unit” we need to be looking toward, and not the gene nor the “meme”.
Information is Structure
Of course, the fundamental “unit” we are talking about here is information, and not limited as is Shannon’s concept to data. The quality that changes data to information is structure, and structure of a particular sort. Like all structure, there is order or patterns, often of a hierarchical or fractal or graph nature. But the real aspect of the structure that is important is the marginal ability of that structure to lead to improvements in entropy production. That is, processes are most adaptive (and therefore selected) that maximize entropy production. Any structure that emerges that is able to reduce the energy gradient faster will be favored.
However, remember, these are probabilistic, statistical processes. Uncertainties in state may favor one structure at one time versus another at a different time. The types of chemical compounds favored in the primordial soup were likely greatly influenced by thermal and light cycles and drying and wet conditions. In biological ecosystems, there are huge differences in seed or offspring production or in overall species diversity and ecological complexity based on the stability (say, tropics) or instability (say, disturbance) of local environments. As noted, these processes are inherently non-deterministic.
As we climb up the chain from the primordial ooze to life and then to humans and our many information mechanisms and technology artifacts (which are themselves embodiments of information), we see increasing complexity and structure. But we do not see uniformity of mechanisms or vehicles.
The general mechanisms of information transfer in living organisms occur (generally) via DNA in genes, mediated by sex in higher organisms, subject to random mutations, and then kept or lost entirely as their host organisms survive to procreate or not. Those are harsh conditions: the information survives or not (on a population basis) with high concentrations of information in DNA and with a priority placed on remixing for new combinations via sex. Information exchange (generally) only occurs at each generational event.
Human cultural information, however, is of an entirely different nature. Information can be made persistent, can be recorded and shared across individuals or generations, extended with new innovations like written language or digital computers, or combined in ways that defy the limits of sex. Occasionally, of course, loss of living languages due to certain cultures or populations dying out or horrendous catastrophes like the Spanish burning (nearly all of) the Mayan’s existing books can also occur [18]. The environment will also be uncertain.
So, while we can define DNA in genes or the ideas of a “meme” all as information, in fact we now see how very unlike the dynamics and structures of these two forms really are. We can be awestruck with the elegance and sublimity of organic evolution. We can also be inspired by song or poem or moved to action through ideals such as truth and justice. But organic evolution does not transpire like reading a book or hearing a sermon, just like human ideas and innovations don’t act like genes. The “meme” is a totally false analogy. The only constant is information.
Some Tentative Implications
The closer we come to finding true universals, the better we will be able to create maximum entropy producing structures. This, in turn, has some pretty profound implications. The insight that keys these implications begins with an understanding of the fundamental nature — and importance — of information. According to Karnani et al [19]:
All would agree that the evolution of life over the past few billion years is truly wondrous. But, what is equally wondrous is that the human species has come to learn and master symbols. That mastery, in turn, has broken the bounds of organic evolution and has put into our hands the very means and structure of information itself. Via this entirely new — and incredibly accelerated — path to information structures, we are only now beginning to see some of its implications:
- Unlike all other organisms, we dominate our environment and have experienced increasing wealth and freedom. Wealth increases and their universal applicability continue to increase at an exponential rate [20]
- We no longer depend on the random variant to maximize our entropy producing structures. We can now do so purposefully and with symbologies and bit streams of our own devising
- Potentially all information variants can be recorded and shared across all human individuals and generations, a complete decoupling from organic boundaries
- Key ideas and abstractions, such as truth, justice and equality, can operate on a species-wide basis and become adopted without massive die-offs of individuals
- We are actively moving ourselves into higher-level energy states, further increasing the potential for wealth and new structures
- We are actively impacting our local environment, potentially creating the conditions for our species’ demise
- We are increasingly engaging all individuals of the human species in these endeavors through literacy, education and access to global information sources. This provides a still further multiplier effect on humanity’s ability to devise and manipulate information structures into more adaptive and highly-ordered states.
The idea of a “meme” actually cheapens our understanding of these potentials.
Ideas matter and terminology matters. These are the symbols by which we define and communicate potentials. If we choose the wrong analogies or symbols — as “meme” is in this case — we are picking the option with the lower entropy potential. Whether I assert it to be so or not, the “meme” concept is an information structure doomed for extinction.


 views
views

 ], which presents an attribute report — similar to a Wikipedia ‘
], which presents an attribute report — similar to a Wikipedia ‘







 ] icon, which then brings up a filter selection at the top of the listing underneath the Attributes header.
] icon, which then brings up a filter selection at the top of the listing underneath the Attributes header.




