Zotero is Perhaps the Most Polished Firefox Extension Yet
Zotero, first released in October, is perhaps the best Firefox extension that most users have never heard of, unless you are an academic historian or social scientist, in which case Zotero is becoming quite the rage. It is also percolating into other academic fields, including law, math and science.
Zotero is a complete research citation platform, or what its developer, George Mason University’s Center for History and New Media (CHnM), calls, “The next-generation research tool.” Zotero allows academics and researchers to extract, manage, annotate, organize, export and publish citations in a variety of formats and from a variety of sources — all within the Firefox browser, and all while obviously the user is interacting directly with the Web.
What it Is
Like all Firefox extensions, Zotero is easy to install. From the Firefox add-on site or the Zotero site itself, a single click downloads the app to your browser. Upon a prompted re-start the app is now active. (Later alerts for any version upgrades are similarly automatic — as for any Firefox extension.)
Upon installation, Zotero puts an icon in your status bar and places new options on menus. When you encounter a site that Zotero supports (currently, mostly university libraries, but also Amazon and major publication outlets as well, totaling more than 150; here is a listing of Zotero’s so-called translators), you will see a folder symbol in your address bar telling you Zotero is active. A single click downloads the citations from that site automatically to your local system.
Citations have traditionally been one of the more “semantically challenging” data sets, with variations in style, order, format, presentation, coverage and you name it rampant. The fact that Zotero supports a given source site means that it understands these nuances and is ready to store the information in a single, canonical representation. Once downloaded, this citation representation can now be easily managed and organized. More importantly, you can now export this internal, standard representation into a multitude of export formats (including, most recently, MS Word). In short, like for-fee citation software in the past, Zotero now provides a free and universal mechanism for managing this chaos.
While the address icon acts to download one or more citations (yes, they also work in groups if there are multiple listings on the page!), choosing the Zotero icon itself invokes the full Zotero as an app within the browser, as this screen shot shows:
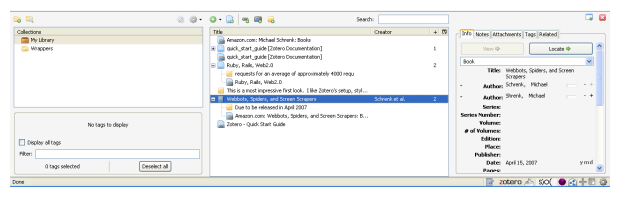
The left panes provide organization and management and tag support; the middle pane shows the active resources; and the right pane shows the structure associated with the active citation. This is all supported with attractive icons and logical tooltips and organization.
Zotero also offers utilities for creating your own scrapers (“translators”) for new sites not yet in the standard, supported roster. This capability is itself an extension to Zotero, called Scaffold, that also points to the building block nature of the core app. (Other utilities such as Solvent from MIT or others surely to come could either enhance or replace the current Scaffold framework.)
What is Impressive
Though supposedly in “beta,” Zotero already shows a completeness, sophistication and attention to detail not evident in most Firefox extensions. Indeed, this system approaches a complete application in its scope and professionalism. The fact it can be so easily installed and embedded in the browser itself is worth noting.
Firefox extensions have continuously evolved from single-function wonders to crude apps and now, as Zotero and a handful of other extensions show, complete functional applications. And, like OSes of the past, these extensions also adhere to standards and practices that make them pretty easy to use across applications. Firefox is indeed becoming a full-fledged platform.
This system is also using the new SQLite local database function (“mozStorage”) in Firefox 2.x to manage the local data (perhaps one of the first Firefox extensions to do so). This provides a clean and small install footprint for the extension, as well as opens it up to other standard data utilities.
What it Implies
So, what Zotero is exemplifying — beyond its own considerable capabilities — are some important implications. First, full-bodied apps, building on many piece-parts, can now be expected around the Fireflox platform. (Indeed, I earlier noted the emergence of such “Web OS” prospects as Parakey, whose developers also come from earlier Firefox legacies. One of those developers, Joe Hewitt, is also the author of the impressive Firebug extension.)
Second, the openness of Firefox for web-centric computing will, as I’ve stated before, continue to put competitive pressure on Microsoft’s Internet Explorer. This is good for all users at large and will continue to spur innovation.
Third, the pending version 2.0 of Zotero is slated to have a server-side component. What we are potentially seeing, then, are local client-side instantiations in the browser that can then communicate with remote data servers. This opens up a wealth of possibilities in social networking and collaboration.
And, last, and more specific to Zotero itself (but also enabled with Firefox’s native RDF support), we are now seeing a complete app framework for dealing with structured information and tagging on the Web. While clearly Zotero has a direct audience for citation management and research, the same infrastructure and techniques used by the system could become a general semantic Web or data framework for any other structured application.
Hmmm. Now that sounds like an opportunity . . . .
 |
An AI3 Jewels & Doubloon Winner |