Squeezed Between Two World Views at the Infocline
 I remember one of my formative jobs at the American Public Power Association when we were running all of APPA’s technical activities. While mostly a lobbying outfit, we were after all in Washington, DC, and were perceived by many to be near some nexus of power and influence. And, because my group did technical stuff, we were a natural magnet for some inventors seeking an edge. And, believe me, some of those folks were real crackpots.
I remember one of my formative jobs at the American Public Power Association when we were running all of APPA’s technical activities. While mostly a lobbying outfit, we were after all in Washington, DC, and were perceived by many to be near some nexus of power and influence. And, because my group did technical stuff, we were a natural magnet for some inventors seeking an edge. And, believe me, some of those folks were real crackpots.
We’d hear claims how this person or that invented radar, or perpetual energy machines, or bendable concrete, and, once, even, cold fusion. Hehe.
In monitoring various ontology and semantic Web mailing lists, claims sometimes arise about the “ontology of everything” or the single, universal ontology that cures cancer or walks on one leg. It makes me smile and think about those past wild claims about radar or perpetual energy.
Some, I believe, when we mention the UMBEL lightweight subject concept reference structure, conjure up similar visions of a universal “ontology of everything”. That is wrong and not our intent. But, UMBEL is trying to straddle two different worlds and world views, and that can often lead to misunderstandings and misperceptions.
This posting is not the first and surely will not be the last on the subject, but it is worthwhile again to try to explain the role of UMBEL from these different angles and with slightly different analogies.
UMBEL is an Infocline
In prior posts, we have described UMBEL as a backbone, as a roadmap to related content, as a lightweight ontology or a lightweight reference structure, and as middleware. In this post, I am going to concentrate on its role as middleware, in its role as residing at the infocline between two different worlds and world views.
The Greek base -cline is often applied to gradual transition layers or changes in gradients or slope. A thermocline, for example, represents the layer between the deep and surface ocean. While there is mixing across this layer, it is slower than within the two parts that it separates. Both parts and the thermocline layer itself have quite different properties and temperatures, even though all are ocean and salty water.
The UMBEL infocline acts in a similar manner. On one side of the UMBEL layer is the Cyc knowledge base, with its self-contained, more-or-less closed world of higher order logics, microtheories regarding thousands of knowledge domains, rich predicates, and coherence. It is venerable, solid and proven, but with its own language and world view. Its purpose is also directed to reasoning and inference, driven from a foundation of (generally not codified outside of Cyc) common sense. It was designed well in advance of the creation of RDF or OWL, indeed in advance of the Internet and Web itself.
On the other side of the UMBEL infocline is the entire Web. This is a chaotic, decentralized, distributed knowledge environment representing untold numbers of world views. The specifications of the semantic Web and its languages and vocabularies have been designed expressly with these differences in mind and the means and structures to link and interrelate them. The Web environment — though not exactly incoherent — is also not in its ground state coherent. Indeed, it is the very purpose of existing semantic Web standards and UMBEL to help provide that coherence.
A key aspect of the Web is its “open world” assumption, defined in SKOS [1] as:
What this means for the Web is that we must assume that the system’s knowledge is incomplete, and that if a statement cannot be inferred from what is explicitly expressed, we still cannot infer it to be false. Adding new information never falsifies a previous conclusion, and most of what we can know about the world will remain unknown. Cyc, on the other hand, can make closed-world assumptions under appropriate conditions.
UMBEL thus must act as a mediator, or middleware, in its role as the interface between these world views. It can lead to tension and turbulence when contemplating or transiting this infocline layer.
The Cyc Reference Knowledge Base
The central purpose of UMBEL is to provide a context for relating information. Once such a purpose for context is embraced, the natural next question is: And what shall be the basis for this context?
A previous post discussed why Cyc was chosen over alternatives as this contextual basis. Ultimately, the reasons for choosing Cyc come down to real practical tools and capabilities such as helping to disambiguate the identities of named entities, mapping ontologies and schema, doing natural language processing, and the sheer provenness of the concept relationships that are at the core of UMBEL.
(Also, as noted many times, others could just as reasonably chose other bases for providing context. The important point, again, is to provide some context over no context.)
We can view the Cyc knowledge base as a complete, albeit large, world unto itself. Like the Earth, it is complex and varied and self-contained. It has its own atmosphere and perspective on the broader universe:

But, like other planets or celestial bodies, Cyc is a world, not the world. There are many different possible worlds with different atmospheres and gravities and temperatures and compositions. And, of course, Cyc is not a physical world at all, but a conceptual “world” representing knowledge and its relationships. We will, however, represent it with the Earth image below.
There is 25 years and perhaps close to 300 person-years of development behind Cyc. It has thousands of able practitioners around the world and has been used in hundreds of meaningful projects and engagements. Since its release in 2002, there have been well in excess of 100,000 downloads of its open-source OpenCyc version.[2]
This legacy and history leads to distinct functional and terminology differences from current semantic Web perspectives. For example, the richness of Cyc predicates does not lead to simple mappings to existing OWL and RDFS properties. The notion of class is different than the closest analog in Cyc, the ‘collection‘. The concept and treatment of individuals and types is different. The 1000 or so microtheory domains in Cyc are not easily transferred or mapped to OWL constructs. Cyc uses reification aggressively to functionally combine concepts from constituent elements, such as “apple tree”. Higher-order logic is not transferable in all cases to the first-order logic (FOL) of the semantic Web. And so forth . . . .
Perhaps most importantly, however, is that Cyc has been designed, built and extended by professional ontologists and related researchers. This brings a degree of consistency and quality control that Web-broad initiatives can not hope to approach.
In our working with Cyc there has been nothing but good will and professionalism from the staff at Cycorp and the Cyc Foundation. But, there are clearly times when world view and terminology can differ, sometimes leading to translation problems and issues. Moreover, attempts to bridge from the Cyc world to the open world assumptions of the general Web means the translation is “lossy”, much like what happens in moving from a 16 million palette of 24-bit colors to something less.
Cleaning Cyc
Here are some statistics showing the relative size and scope of the ResearchCyc and OpenCyc versions of Cyc, current as of the last official distributions [3]:
| Category | OpenCyc | ResearchCyc |
| Reifiied Terms (Constants and NARTs) | 263,332 | 303,340 |
| Assertions | 2,040,330 | 2,964,161 |
| Deductions | 323,751 | 1,305,354 |
| Unique Predicates (Properties) [2] | 17 (OWL) | ~16,000 |
| Disk Storage (KBs) [4] | 495,104 | 566,400 |
The sheer size and sophistication of either version is too great for easy comprehension and linkage by standard Web resources. Thus, the UMBEL project set out to determine and derive the most fundamental concepts from within OpenCyc. What was desired was a tractable set of subject concept “hub” nodes from within OpenCyc. A further design criterion was to maintain a 100% consistency with OpenCyc for this subset of subject concepts in order for UMBEL to preserve linkage into the Cyc knowledge base.
A subsequent post will relate in detail the nine-month (and continuing!) vetting and extraction process applied to Cyc, the result of which is currently the identification of about 21,000 subject concepts. These are schematically illustrated by the yellow dots on our Cyc Earth representation:
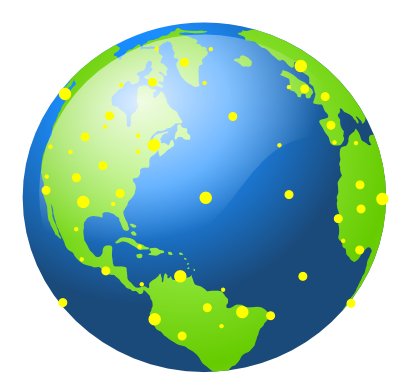
Of course, these yellow dots are not really physical locations on a globe. Rather, they represent important “hub” locations within the virtual Cyc knowledge “space”.
UMBEL: A Lightweight Skein
Once removed from the broader knowledge base, we now have a simple skein of these 21,000 subject concepts and their interrelations. We can show this lightweight structure as a ball of subject concept nodes (in red) connected to one another via their graph edges. We can represent this lightweight skein as follows, which has similarities to a hairnet with the nodes represented by the knots (in red) in the net:
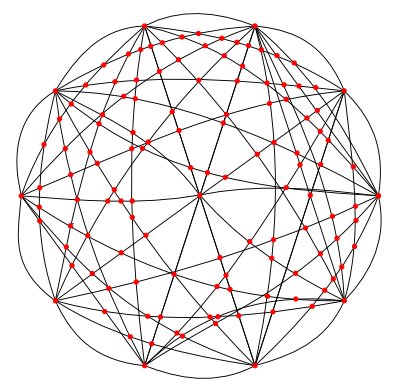
This simplistic wireframe representation has been presented before for all 21,000 UMBEL nodes via the Cytoscape graph visualization software (see figure right; click for larger size).
 The following table shows that the overall size and complexity of Cyc has been reduced by 1-2 orders of magnitude through this cleaning exercise, resulting in a lightweight UMBEL structure about 5-10% of the original size:
The following table shows that the overall size and complexity of Cyc has been reduced by 1-2 orders of magnitude through this cleaning exercise, resulting in a lightweight UMBEL structure about 5-10% of the original size:
| Category | OpenCyc | ResearchCyc | UMBEL |
| Terms or Concepts | 263,332 | 303,340 | 21,057 |
| Assertions | 2,040,330 | 2,964,161 | 285,700 |
| Deductions | 323,751 | 1,305,354 | — |
| Unique Predicates (Properties) [2,5] | 17 (OWL) | ~16,000 | 18 |
| Disk Storage (KBs) [4] | 495,104 | 566,400 | 14,445 |
Very striking is the predicate reduction, which is both a key source of “lossiness” and a challenge in maintaining a meaningful OWL and RDFS correspondence with the original Cyc. However, since the purpose of UMBEL is context and not reasoning or inference, this reduction is appropriate and understandable.
The ‘Hairnet Over the Basketball’
Metaphorically, we can now re-apply this UMBEL skein over the Cyc knowledge base. We have described this visual metaphor as the “hairnet over the basketball,” with UMBEL being the hairnet, and Cyc (Earth) the basketball:

Note that the UMBEL skein can act and be used fully independently from the underlying Cyc structure or not.
21,000 Docking Ports for an Open World
This UMBEL lightweight skein or wireframe structure now is ready to act as middleware, to play its role as an infocline. Each of UMBEL’s 21,000 subject concepts is, in effect, a “docking port” to which external Web data can “attach”. Once attached, this data can then be related to other Web data via the subject concept relationships in the UMBEL skein. This docking and attachment mechanism can be visualized as follows (click to enlarge):
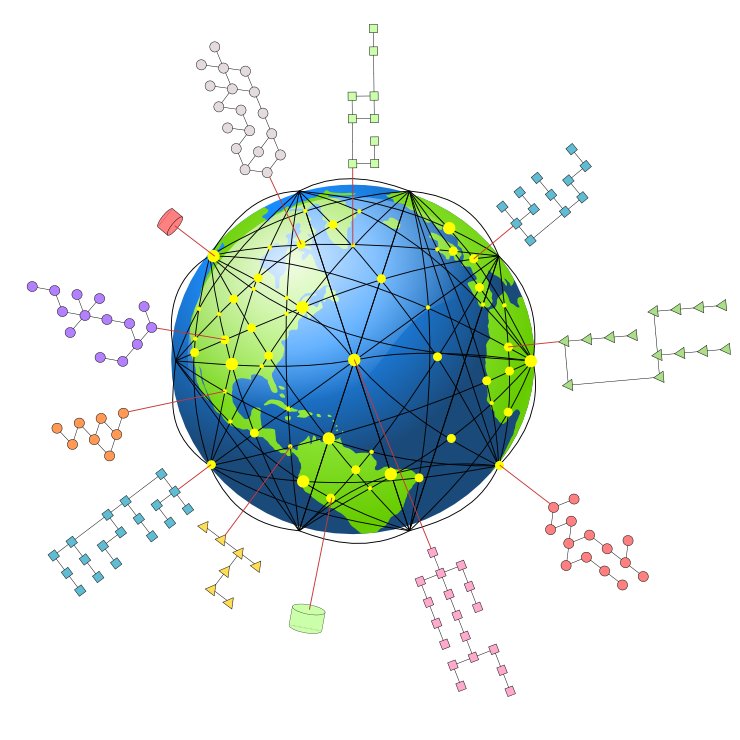
If you mentally remove the Earth figure (Cyc) above, the UMBEL skein acts solely as a context reference structure for other Web data through its lightweight SKOS taxonomy structure (narrowerTransitive and broaderTransitive). These are the internal edge relationships of the wireframe structure with the red nodes above.
Though lightweight, this structure is surprisingly powerful in that it also enables tie-ins with external ontology classes — what Fred Giasson has called ‘exploding the domain‘ — and provides a reference context for Web data. Without these docking ports via UMBEL’s subject concepts, there is no contextual frame of reference and these Web data bits essentially tumble aimlessly in a dark knowledge space.[6]
But one need not stop at the infocline wireframe layer of UMBEL. Because each subject concept (“docking port”) has a direct correspondence to Cyc, we can dive more deeply into the Cyc knowledge environment. First through OpenCyc and then (via licensing or other arrangements) into ResearchCyc or the full Cyc, another dimension of tools and capabilities can become available. We now have backup and support to assess mappings and assignments and inferences and reasoning.
Will everyone want such capabilities? Most will not.
But it also surely does not hurt to have these value-added pathways so readily available for use and exploitation.
Some Context is Better than No Context at All
Some perhaps in the Cyc community may look at this picture and say, Whoa!: We’re giving Web denizens loaded Cyc guns via the UMBEL infocline to harm themselves and others.
Perhaps so. But this is also why we have courses on firearms safety and practice ranges for gaining the experience. Ontology mapping of any nature in an open world requires attention and skill to maintain quality.
The open world circumstances have already shown challenges with sameAs assignments and will certainly be exacerbated as we extend to class mappings in ontologies and inferencing. Quality and provenance will assert their prominence. Who do you trust and who is capable? But haven’t these always been operative questions?
Some perhaps in the broader Web community may go, Whoa! We are free and independent actors who hate any sniff of possible centralized Big Brother crap. Why UMBEL? Why Cyc? I want to free-form tag and twitter to my heart’s content.
OK, well, sure. But how can the Web of data meaningfully expand without reference points, structure and context? Though we may have foundational semantic Web standards in place, if we are going to meaningfully inter-relate data, we also need context and semantics.
UMBEL and Cyc offer one set of contexts, semantics and tools. Whether they are the best or not is a matter for the market to decide. But I think it will rapidly become clear that future Linked Data that is published without context will remain largely unused data. The question now going forward is not the rejection of context but deciding what contextual frameworks work better, are easy to implement, and are readily understood.
So, I think the game has changed and I’d like to believe for the better. UMBEL has placed a marker down — and it’s smack dab in the middle.
Yes I’m stuck in the middle with you,
And I’m wondering what it is I should do,
It’s so hard to keep this smile from my face,
And knowledge, yeah, is all over the place,
Cyc to the left of me, Open Web to the right,
Here I am, stuck in the middle with you. [7]