Today, the value of the information contained within documents created each year in the United States represents about a third of total gross domestic product, or an amount of about $3.3 trillion.[1] Moreover, about $800 billion of these expenditures are wasted and are readily recoverable by businesses, but are not. Up to 80% of all corporate information is contained within documents. Perhaps up to 35% of all company employees in the U.S. can be classified as knowledge workers using and relying on documents. So, given these factors, how could such large potential cost savings from better document use be overlooked?
Previous installments in this series have looked at issues of private v. public information, barriers to collaboration, and solutions as being too expensive as possible reasons for why these potential savings are not realized. This fourth installment looks at a fourth reason; namely, what might be called issues of attention, perception or psychology. Interesting observations in this area come from disciplines as diverse as sales, behaviorial psychology, economics and operations research.
The SPIN Rationale
One explanation for this lack of attention can be described by the fact that document problems are still in the area of implicit needs as opposed to explicit needs. In other words, the perception of the problem is still situational but has not yet become concrete in terms of bottom-line impacts.
In Neil Rackham’s SPIN sales terminology (Situation → Problems → Implications → Needs/pay-off),[2] the enterprise document market is still at a “situational” level of understanding. Decisions to buy or implement solutions are largely strategic and limited to early adopters that are the visionaries in their market segments. The inability to express and quantify the implications of not realizing the value of document assets means that ROI analysis can not justify a deployment and market growth can not cross the chasm.
The situation begins with the inability to quantify the importance of both internal and external document assets to all aspects of the enterprise’s bottom line. Early adopters of enterprise content software typically capture less than 1% of valuable internal documents available; large enterprises are witnessing the proliferation of internal and external Web sites, sometimes exceeding thousands; use of external content is presently limited to Internet search engines, producing non-persistent results and no capture of the investment in discovery or results; and “deep” content in searchable databases, which is common to large organizations and represents 90% of external Internet content, is completely untapped. Indeed, the issue of poor document use in an organizaation can be seen in terms of the figure below:
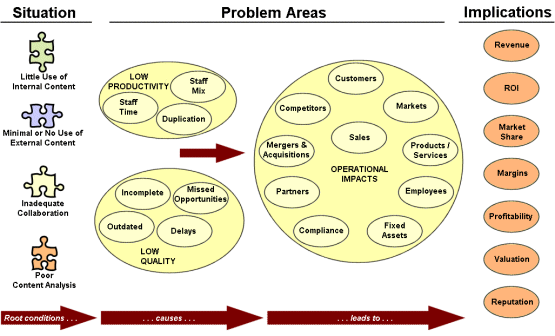
The diagram indicates that these root conditions or situations cause problems in low quality of decisions or low staff productivity. For examples, documents or proposals get duplicated without knowledge of prior effort that could be leveraged; opportunities are missed; or outdated or incomplete information is applied to various tasks. These root problems can impact virtually all aspects of the organization’s operations: sales are lost; competitors are overlooked; compliance requirements are missed. These problems can lead to significant bottom-line implications from revenue and market share, to reputation and valuation and even indeed survival.
Thus, in the view of the SPIN model, the lack of attention to the issue of document assets can, in part, be ascribed to the sales or investigatory process. Specific questions have not been posed that move the decision maker from a position of situational awareness to one of explicit bottom-line implications.
There is undoubtedly truth to this observation. Sales of large document solutions to enterprises require a consultative sales approach and significant education of the market is required. As a first-order circumstance, this implies long sales leadtimes and the dreaded “educating the market” that most VCs try to avoid.
But there are even larger factors at play than a lack of explicitness regarding document assets.
The Ubiquitous and Obvious Are Often Overlooked
Put your index finger one inch from your nose. That is how close — and unfocused — document importance is to an organization. Documents are the salient reality of a knowledge economy, but like your finger, documents are often too close, ubiquitous and commonplace to appreciate.
The dismissal of the ubiquitous, common or obvious can be seen in a number of areas. In terms of R&D and science, this issue has been termed “mundane science” wherein most academic research topics exclude many of the issues that affect the largest number of people or have the most commonality. [3] In organizational and systems research, such issues have also been the focus of better, more rigorous problem identificaton and analysis techniques such as the “rational model” or the “theory of constraints” (TOC).[4]
Compounding the issue of the overlooked obvious is the lack of a quantified understanding of the problem. There is an old Chinese saying that roughly translated is “what cannot be measured, cannot be improved.” Many corporate executives surely believe this to be the case for document creation and productivity.
More Specifically: Bounded Awareness
Chugh and Bazerman have recently coined a term “bounded awareness” for the phenomenon of missing easily observed and relevant data.[5] As they explain:
“Bounded awareness is a phenomenon that encompasses a variety of psychological processes, all of which lead to the same error: a failure to see, seek, use, or share important and relevant information that is easily seen, sought, used, or shared.”
The authors note the experiments from Simons[6] that extend Neisser’s 1979 video in which a person in a gorilla costume walks through a basketball game, thumping his chest, and is clearly and comically visible for more than five seconds, but is not generally recalled by observers without prompting.
Chugh and Bazerman classify a number of these phenomena, with two most applicable to the document assets problem:
- Inattentional blindness — direct information when attention is drawn or focused elsewhere
- System neglect — this phenomenom is the tendency to undervalue a broader, pivotal factor to subsidiary ones, as in for example the effect of campaign finance-reform on specific political issues. In the document assets case, the general role of document access and management is neglected as a system over more readily understood specific issues such as search or spell checking. In other words, people tend to value issues that are more clearly seen as end states or outcomes.
Note the relation of these studies by behaviorial psychologists to the SPIN terminology of the sales executive. Clearly, perceptual studies by scientists will lead to better understandings of market outreach.
Perceptions of Intractability?
An earlier installment in this series noted the high cost of enterprise content solutions, more generally linked to software that performed poorly and did not scale. In computer science, intractable problems are those which take too long to execute, the problem may not be computable, or we may not know how to solve the problem (e.g., problems in artificial intelligence). Tractable problems can run in a reasonable amount of time for even very large amounts of input data. Intractable problems require huge amounts of time for even modest input sizes.[7]
At low scales, the efficiency of various computer algorithms is not terrible important because multiple methods can produce acceptable performance times. But at large scales whether a problem is tractable or not is not fixed: it depends critically on the efficiency of the algorithm applied to the problem. Let’s take for example the issue of searching text items:
Take n to represent the number of keys in a list, and let O represent the order of the number of comparison operations required to find an entry. For a small number of n items, the algorithm used is unimportant, and even a slow sequential search will work well. Sequentially searching the list until the desired match is found is O (n), or linear time. If there are 1000 items in a list, and there is an equal probability of searching for any item in the list, on average it will require n/2 = 500 comparisons to find the item (assuming all items already are on the list). A binary search works by dividing the list in half after each comparison. This is logarithmic time O (log n ), much faster than linear time. For a 1000 item example it works out to about 10 comparisons. An O (1) operation, such as hashing, is applicable when some algorithm computes the item location and then retrieves it. On large lists it will significantly outperform a binary search, because it makes no comparisons. (It is a little more complicated than that because there may be collisions for the same address computed for different keys.) However, if the location is already known, even the hashing computation is unnecessary. This is what happens with direct addressing (the technique used by BrightPlanet), which will obtain the desired item in a single step.[8]
Poorly performing algorithms at large scales can require processing times for updates that take longer than the period between updates, and, thus, at least for that algorithm, are intractable at those scales.
This is one of the key and perceived problems to most document processing software at large scales — their computational inefficiencies do not allow updates to occur for the meaningful document volumes important to larger organizations. Whether the specific reasons are known by company managers and IT personnel, it is a widespread understanding — correct for most vendors — within the marketplace.
Since BrightPlanet‘s core index work engine is more efficient than other approaches (due, in part, to better sorting mechanisms as noted above, but also due to other factors), current perceived limits of intractability may not apply. However, these advances are still not generally known. Until broader understanding for how more contemporary approaches to document use and management are gained, perceptions of past poor performance will limit market acceptance.
Educating the Market
Thus, factors of awareness, attention and perception are also limiting the embrace of meaningful approaches to improve document access and use and achieve meaningful cost savings. These challenges may mean that the document intelligence and document information automation markets still fall within the category of needing to “educate the market.” Since this category is generally dreaded by most venture capitalists (VCs), that perception is also acting to limit the achievable improvements and cost savings available to this market.
But there is perhaps a very important broader question that remains open here: educating the market through the individual customer (viz. the SPIN sale) vs. educating the market through breaking market-wide bounded awareness. In fact the latter, much as what occurred with data warehousing 15-20 years ago, can create entirely new markets. This latter category should perhaps be of much greater VC interest with its accompanying potential for first-mover advantage.
[1] Michael K. Bergman, “Untapped Assets: The $3 Trillion Value of U.S. Enterprise Documents,”
BrightPlanet Corporation White Paper, July 2005, 42 pp. All 80 references, 150 citations and calculations are fully documented in the full paper. See
http://www.brightplanet.com/technology/whitepapers.asp.
[2] Neil Rackham, SPIN Selling, McGraw Hill, 197 pp., 1988.
[3] Daniel M. Kammen and Michael R. Dove, “The Virtues of Mundane Science,” Environment, Vol. 39 No. 6, July/August 1997. See http://ist-socrates.berkeley.edu/~rael/Mundane_Science.pdf
[4] Victoria Mabin, “Goldratt’s ‘Theory of Constraints’ Thinking Processes: A Systems Methodology linking Soft with Hard,” The 17th International Conference of The System Dynamics Society and the 5th Australian & New Zealand Systems Conference, July 20 – 23, 1999, Wellington, New Zealand, 12 pp. See http://www.systemdynamics.org/conf1999/PAPERS/PARA104.PDF
[5] Dolly Chugh and Max Bazerman, “Bounded Awareness: What You Fail to See Can Hurt You,” Harvard Business School Working Paper #05-037, 35 pp., August 25, 2005 revision. See http://www.people.hbs.edu/mbazerman/Papers/05-037.pdf
[6] See the various demos available at http://viscog.beckman.uiuc.edu/djs_lab/demos.html.
[7] Professor Constance Royden, College of the Holy Cross, course uutline for CSCI 150, Tractable and Intractable Problems, Spring 2003. See http://mathcs.holycross.edu/~croyden/csci150spr03/notes/lec33_tractable.html
[8] R. L. Kruse, Data Structures and Program Design, Prentice Hall Press, Englewood Cliffs, New Jersey, 1987.
| NOTE: This posting is part of a series looking at why document assets are so poorly utilized within enterprises. The magnitude of this problem was first documented in a BrightPlanet white paper by the author titled, Untapped Assets: The $3 Trillion Value of U.S. Enterprise Documents. An open question in that paper was why more than $800 billion per year in the U.S. alone is wasted and available for improvements, but enterprise expenditures to address this problem remain comparatively small and with flat growth in comparison to the rate of document production. This series is investigating the various technology, people, and process reasons for the lack of attention to this problem. |





