





Collex is the Next Example in a Line of Innovative Tools from the Humanities
I seem to be on a string of discovery of new tools from unusual sources — that is, at least, unusual for me. For some months now I have been attempting to discover the “universe” of semantic Web tools, beginning obviously with efforts that self-label in that category. (See my ongoing Sweet Tools comprehensive listing of semantic Web and related tools.) Then, it was clear that many “Web 2.0” tools potentially contribute to this category via tagging, folksonomies, mashups and the like. I’ve also been focused on language processing tools that relate to this category in other ways (a topic for another day.) Most recently, however, I have discovered a rich vein of tools in areas that take pragmatic approaches to managing structure and metadata, but often with little mention of the semantic Web or Web 2.0. And in that vein, I continue to encounter impressive technology developed within the humanities and library science (see, for example, the recent post on Zotero).
To many of you, the contributions from these disciplines have likely been obvious for years. I admit I’m a slow learner. But I also suspect there is much that goes on in fields outside our normal ken. My own mini-epiphany is that I also need to be looking at the pragmatists within many different communities — some of whom eschew the current Sem Web and Web 2.0 hype — yet are actually doing relevant and directly transferable things within their own orbits. I have written elsewhere about the leadership of physicists and biologists in prior Internet innovations. I guess the thing that has really surprised me most recently is the emerging prominence of the humanities (I feel like the Geico caveman saying that).
Collex is the Next in A Fine Legacy
The latest discovery is Collex, a set of tools for COLLecting and EXhibiting information in the humanities. According to Bethany Nowviskie, a lecturer in media studies at the University of Virginia, and a lead designer of the effort in her introduction, COLLEX: Semantic Collections & Exhibits for the Remixable Web:
Collex is a set of tools designed to aid students and scholars working in networked archives and federated repositories of humanities materials: a sophisticated collections and exhibits mechanism for the semantic web. It allows users to collect, annotate, and tag online objects and to repurpose them in illustrated, interlinked essays or exhibits. Collex functions within any modern web browser without recourse to plugins or downloads and is fully networked as a server-side application. By saving information about user activity (the construction of annotated collections and exhibits) as “remixable” metadata, the Collex system writes current practice into the scholarly record and permits knowledge discovery based not only on the characteristics or “facets” of digital objects, but also on the contexts in which they are placed by a community of scholars. Collex builds on the same semantic web technologies that drive MIT’s SIMILE project and it brings folksonomy tagging to trusted, peer-reviewed scholarly archives. Its exhibits-builder is analogous to high-end digital curation tools currently affordable only to large institutions like the Smithsonian. Collex is free, generalizable, and open source and is presently being implemented in a large-scale pilot project under the auspices of NINES.
(BTW, NINES stands for the Networked Infrastructure for Nineteenth-century Electronic Scholarship, a trans-Atlantic federation of scholars.)
The initial efforts that became Collex were to establish frameworks and process within this community, not tools. But the group apparently recognized the importance of leverage and enablers (i.e, tools) and hired Erik Hatcher, a key contributor to the Apache open-source Lucene text-indexing engine and co-author of Lucene in Action, to spearhead development of an actually usable tool. Erik proceeded to grab best-of-breed stuff in area such as Ruby and Rails and Solr (a faceted enhancement to Lucene that has just graduated from the Apache incubator), and then to work hard on follow-on efforts such as Flare (a display framework) to create the basics of Collex. A sample screenshot of the application is shown below:
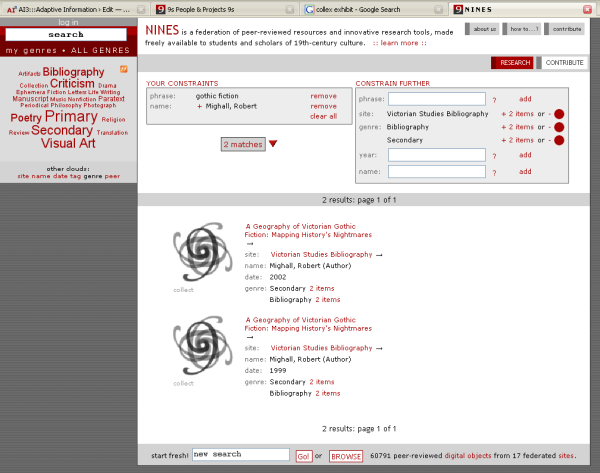
The Collex app is still flying under the radar, but it has sufficient online functionality today to support annotation, faceting, filtering, display, etc. Another interesting aspect of the NINES project (but not apparently a programmatic capability of the Collex software itself) is it only allows “authoritative” community listings, an absolute essential for scaling the semantic Web.
You can play with the impressive online demo of the Collex faceted browser at the NINES Web site today, though clearly the software is still undergoing intense development. I particularly like its clean design and clear functionality. The other aspect of this software that deserves attention is that it is a server-side option with cross-browser Ajax, without requiring any plugins. It works equally within Safari, Firefox and Windows IE. And, like the Zotero research citation tool, this basic framework could easily lend itself to managing structured information in virtually any other domain.
Collex is one of the projects of Applied Research in Patacriticism, a software development research team located at the University of Virginia and funded through an award to professor Jerome McGann from the Andrew Mellon Foundation. (“Shuuu, sheeee. Impressive. Most impressive.” — Darth Vader)
(BTW, forgive my sexist use of “guys” in this post’s title; I just couldn’t get a sex-neutral title to work as well for me!)
 |
An AI3 Jewels & Doubloon Winner |

Thanks very much for this nice, perceptive review! We’re really excited about the Collex tool and we think it has broad potential. Next on our plate is a mid-February release of the NINES material in Collex to the scholarly community. We hope we’ll get lots of tagging and annotating going on in the sidebar (the design of which is currently under heavy revision). We’re also hard at work on the EX in Collex — a user-friendly exhibit builder that will let you transform your collections into annotated bibliographies, course syllabi, chronologies, and illustrated essays. So stay tuned!
Bethany,
You are welcome, and thanks for the nice work. BTW, I will obviously be adding Collex to the Sweet Tools listing, which is due for another update. However, I didn’t want to delay getting coverage of Collex posted!
Thanks, Mike