




This is the last entry in our recent series on data federation. This post compares interoperability models and concludes with a new approach for promoting enterprise interoperability and innovation.
We are now about to conclude this mini-series on data federation. In earlier posts, I described the significant progress in climbing the data federation pyramid, today’s evolution in emphasis to the semantic Web, the 40 or so sources of semantic heterogeneity, and tools and methods for processing and mediating semantic information. We now conclude with a comparison of implementation models for semantic interoperability.
Guido Vetere, an IBM research scientist and one of the clearest writers on this subject has said:
Despite the increasing availability of semantic-oriented standards and technologies, the problem of dealing with semantics in Web-based cooperation, taken in its generality, is very far from trivial, not only for practical reasons, but also because it involves deep and controversial philosophical aspects. Nevertheless, for relatively small communities dealing with well-founded disciplines such as biology, concrete solutions can be effectively put in place. In fact, most of the data structures will represent commonly understood natural kinds (e.g. microorganisms), well-studied processes (e.g. syntheses) and so on. Still, significant differences in the way actual data structures are used to represent these concepts might require complex mappings and transformations. [1]
Yet there are easier ways and harder ways to achieve interoperability. Paul Warren, a frequent citation in this series, observes:[2]
I believe there will be deep semantic interoperability within organizational intranets. This is already the focus of practical implementations, such as the SEKT (Semantically Enabled Knowledge Technologies) project, and across interworking organizations, such as supply chain consortia. In the global Web, semantic interoperability will be more limited.
I agree with this observation. But why might this be the case? Before we conclude why some models for semantic interoperation may work better and earlier than others, let’s first step back and look at four model paradigms.
Four Paradigms of Semantic Interoperability
In late 2005, G. Vetere and M. Lenzerini (V&L) published an excellent synthesis description of “Models for Semantic Interoperability in Service Oriented Architectures” in the IBM Systems Journal. [3] Though obviously geared to an SOA perspective, the observations ring true for any semantic-oriented architecture. These prototypical patterns provide a solid basis for discussing the pros and cons of various implementation approaches.
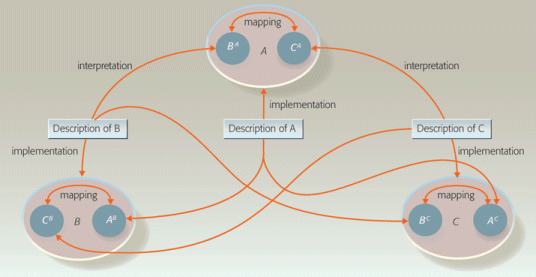
Any-to-Any Centralized
The ‘Any-to-Any Centralized’ model (also called by Vetere as unmodeled-centralized in the first-cited paper [1]), is “tightly-coupled” in that the mapping requires a semantic negotiation or understanding between the integrated, central parties. The integrated pieces (services, in this instance) are usually atomic, independent and self-contained, The integration takes place within a single instantiation and is not generalized.
V&L diagrammed this model as follows:
Any-to-Any Centralized Semantic Interoperability Model (reprinted from [3])
It is clear in this model that there is no ready “swap out” of components. There needs to be bilateral agreements betweeen all integration components. Semantic errors can only be determined at runtime.
This model is really the traditional one used by system integrators (SIs). It is a one-off, high level-of-effort, non-generalized and non-repeatable model of integration that only works in closed environments. No ontology is involved. It is the most costly and fragile of the interoperability models.
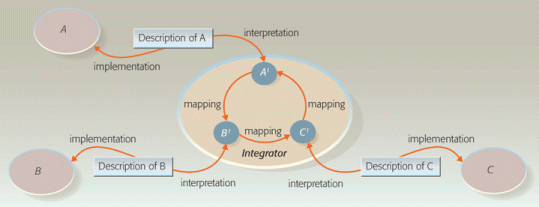
Any-to-One Centralized
In V&L’s ‘Any-to-One Centralized’ model (also known as modeled-centralized), while it may not be explicit, there is a single “ontology” that is a superset of all contributing systems. This “ontology” framework may often take the form of an enterprise service bus, where its internal protocols provides the unifying ontology.
This interoperability model, too, is quite costly in that all suppliers (or service providers) must conform to the single ontology.
It is often remarked that the number of mappings required for the entire system is significantly reduced in any-to-one models, decreasing (in the limit) from N × (N − 1) to N, where N is the number of services involved. However, the reduction in the number of mappings is not the striking difference here. The real difference is in the existence of a business model.
V&L diagrammed this model as follows:
Any-to-One Centralized Semantic Interoperability Model (reprinted from [3])
The extensibility of the business model is therefore the key to the success of this interoperability pattern. Generally, in this case, the enterprise makes the determination of what components to interoperate with and conducts the mapping.
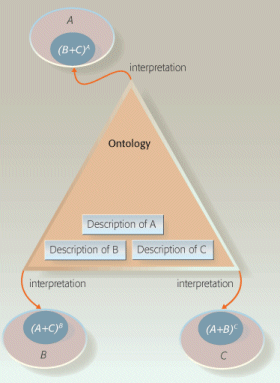
Any-to-Any Decentralized
The normal condition in ‘loosely-coupled’ environments such as the Web in general is called the ‘Any-to-Any Decentralized’ model (also known as unmodeled-decentralized). In this model, the integration logic is distributed, and there are not shared ontologies. This is a peer-to-peer system, sometimes known as P2P information integration systems or ’emergent semantics.’
The semantics are distributed in systems that are strongly isolated from one another, and though grids can help the transaction aspects, much repeat effort occurs as a function of the interoperating components. V&L diagrammed this model as follows:
Any-to-Any Decentralized Semantic Interoperability Model (reprinted from [3])
It is thus the responsibility of each party to perform the mapping to any other party with which it desires to interoperate. The lack of a central model acts to greatly increase the effort needed for much interoperability at the system level.
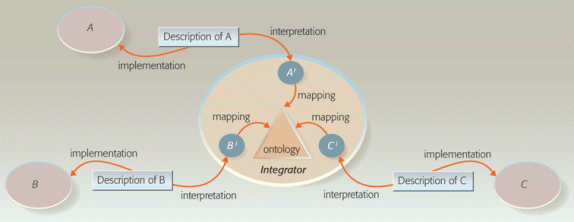
Any-to-One Decentralized
One way to decrease the effort required is to adopt the ‘Any-to-One Decentralized’ model (also modeled-decentralized) wherein an ontology model provides the mapping guidance. (Note there may need to be multiple layers of ontologies from shared “upper level” ones to those that are domain specific).
In this model, the integration logic is distributed by any service or component implementation, based on a shared ontology. It is this model that is the one generally referred to as the semantic Web approach. (In Web services, this is accomplished via the multiple WS* web service protocols.)
According to V & L:
. . . having business models specified in a sound and rich ontology language and having them based on a suitable foundational layer reduces the risk of misinterpretations injected by agents when mapping their own conceptualizations to such models. A suitable coverage of primitive concepts with respect to the business domain (completeness) that entails the possibility to progressively enhance conceptual schemas (extensibility) are also key factors of success in the adoption of shared ontologies within service-oriented infrastructures. But still there is the risk of inaccuracy, misunderstandings, errors, approximations, lack of knowledge, or even malicious intent that need to be considered, especially in uncontrolled, loosely coupled environments.
V&L then diagrammed this model as follows:
Any-to-One Decentralized Semantic Interoperability Model (reprinted from [3])
In this model, the ontology (or multiple ontologies) need to comprehensively include the semantics and concepts of all participating components. Thus, while the components are “decentralized,” the ontology growth must somehow be “centralized” in that it needs to expand and grow.
A collaboration environment similar to say, Wikipedia, could accomplish this task, though the issues of authoritativeness and quality would also arise as they have for Wikipedia.
Alternative Approaches to Semantic Web Ontologies
There are a number of ways to provide a “centralized” ontology view for this semantic Web collaboration environment. Xiaomeng Su provides three approaches for thinking about this problem:[4]
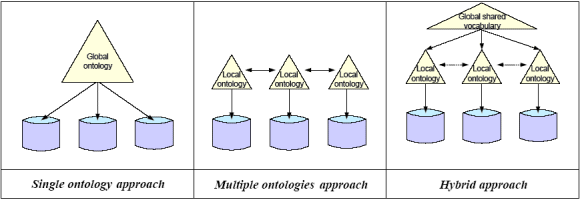
Approaches to Semantic Web Ontologies (modified from [4])
The simplest, but least tractable approach given the anarchic nature of the Web, is to adopt a single ontology (this is what is implied in the ‘Any-to-One Decentralized’ interoperability model above). A more realistic approach is where there are multiple world views or ontologies, shown in the center of the diagram. This approach recognizes that different parties will have different world views, the reconciliation of which requries semantic mediation (see previous post in this series). Finally, in order to help minimize the effort of mediation, some shared general ontologies may be adopted. This hybrid approach can also rely on so-called upper-level ontologies such as SUMO (Suggested Upper Merged Ontology) or the Dublin Core. While semantic mediation is still required between the local ontologies, the effort is somewhat lessened.
The Best Model Depends on Circumstance
These models illustrate trade-offs and considerations depending on the circumstance where interoperability is an imperative.
For the semantic Web, which is the most difficult environment given the lack of coordination possible between contributing parties, the best model appears to be the ‘Any-to-One Decentralized’ model with a hybrid approach to the ontology model. Besides the need for ontologies to mature, the means for semantic mediation and the tools to help automate the tagging and mediation process also need to mature significantly. Though isolated pockets
Comprehensive Interfaces: A Hybrid Model for Enterprise Interoperability
I have argued in previous posts that enterprises are likely to be the place where semantic interoperability first proves itself. This is because, as we have seen above, centralized models are a simpler design and easier to implement, and because enterprises can provide the economic incentive for contributing players to conform to this model.
So, given the model discussions above, how might this best work?
First, by definition, we have a “centralized” model in that the enterprise is able to call the shots. Second, we do want a “One” model wherein a single ontology governs the semantics. This means that we can eliminate requirements and tools to mediate semantic heterogeneities.
On the other hand, we also want a “loosely-coupled” system in that we don’t want a central command-and-control system that requires upfront decisions as to which components can interoperate.
In other words, how can we gain the advantages of a free market for new tools and components at minimum cost and technical difficulty?
The key to answering this seeming dilemma is to “fix” the weaknesses of the ‘Any-to-One Centralized’ model while retaining its strengths. This hybrid shift is shown by this diagram:
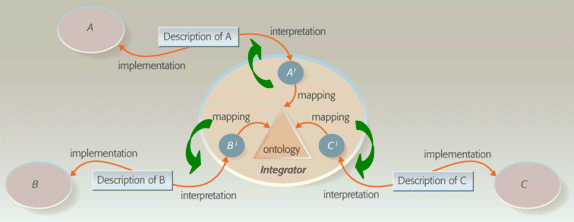
Shifting Interoperability to the Supplier (modified from [3])
The diagram indicates that the enterprise adopts a single ontology model, but exposes its interoperability framework through a complete “recipe book” for interoperating to which external parties may embrace (the green arrows).
The idea is to expand beyond single concepts such as APIs (application programming interfaces), ontologies, service buses and broker and conversion utilities to one of a complete set of community standards, specifications and conversion utilities that enables any outside party to interoperate with the enterprises central model. The interface thus becomes the comprehensive objective, comprehensively defined.
By definition, then, this type of interoperability is “loosely coupled” in that the third (external) party can effect the integration without any assistance or guidance (other than the standard “recipe book”) from the central authority. The central system thus becomes a “black box” as traditionally defined. This means that any aggressive potential supplier can adapt its components to the interface in order to convince the enterprise to buy its wares or services.
This design can suffer the weakness of the potential inefficiencies that result from loosely-coupled integration. However, if the new component proves itself and fits the bill, the central enterprise authority always has the option to go to more efficient, tightly-coupled integration with that third party to overcome any performance bottlenecks.
It should thus be possible for enterprises (central authorities) to both write these comprehensive “recipe books” and to establish “proof-of-concept” interoperability labs where any potential vendor can link in and prove its stuff. This design shifts the cost of overcoming barriers to entry to the potential supplier. If that supplier believes its offerings to be superior, it can incur the time and effort of coding to the interface and then demonstrating its superiority.
There are very exciting prospects in such an entirely new procurement and adoption model that I’ll be discussing further in future postings.
A key to such a design, of course, is comprehensive and easily implemented interfaces. Once comprehensive approach to a similar design is provided by Izza et al.[5] The absolute cool thing about this new design is that today’s new standards and protocols provide easy means for third parties to comply. This new design completely overcomes the limitations of the prior proprietary approaches for enterprises involving high-cost ETL (extract, transform, load) or their later enterprise service bus (ESB) cousins.
| NOTE: This posting is part of an occasional series looking at a new category that I and BrightPlanet are terming the eXtensible Semantic Data Model (XSDM). Topics in this series cover all information related to extensible data models and engines applicable to documents, metadata, attributes, semi-structured data, or the processing, storing and indexing of XML, RDF, OWL, or SKOS data. A major white paper will be produced at the conclusion of the series. |
[1] G. Vetere, “Semantics in Data Integration Processes,” presented at NETTAB 2005, Napoli, October 4-7, 2005. See http://www.nettab.org/2005/docs/NETTAB2005_VetereOral.pdf.
[2] Paul Warren, “Knowledge Management and the Semantic Web: From Scenario to Technology,” IEEE Intelligent Systems, vol. 21, no. 1, 2006, pp. 53-59. See http://dsonline.computer.org/portal/site/dsonline/menuitem.9ed3d9924aeb0dcd82ccc6716bbe36ec/index.jsp?&pName=dso_level1&path=dsonline/2006/02&file=x1war.xml&xsl=article.xsl&
[3] G. Vetere and M. Lenzerini, “Models for Semantic Interoperability in Service Oriented Architectures, in IBM Systems Journal, Vol. 44, November 4, 2005, pp. 887-904. See http://www.research.ibm.com/journal/sj/444/vetere.pdf
[4] Xiaomeng Su, “A Text Categorization Perspective for Ontology Mapping,” a position paper. See http://www.idi.ntnu.no/~xiaomeng/paper/Position.pdf.
[5] Saïd Izza, Lucien Vincent and Patrick Burlat, “A Unified Framework for Enterprise Integration: An Ontology-Driven Service-Oriented Approach,” pp. 78-89, in Pre-proceedings of the First International Conference on Interoperability of Enterprise Software and Applications (INTEROP-ESA’2005), Geneva, Switzerland, February 23 – 25, 2005, 618 pp. See http://interop-esa05.unige.ch/INTEROP/Proceedings/Interop-ESAScientific/OneFile/InteropESAproceedings.pdf.
